Publications
Our research has been published at top HPC and system conferences (e.g., SC, PPoPP, ASPLOS, DAC, ICS, IPDPS, ICPP, CLUSTER, DATE and Euro-Par) and journals (e.g., TC, TPDS, TCAD, TACO, TODAES, JPDC and PARCO), and most of our papers provide open-source code. Welcome to evaluate and reproduce our work!
2024
Authors: Chenxi Li, Boyuan Zhang, Yongqiang Duan, Yang Li, Zuochang Ye, Weifeng Liu, Dingwen Tao, Zhou Jin
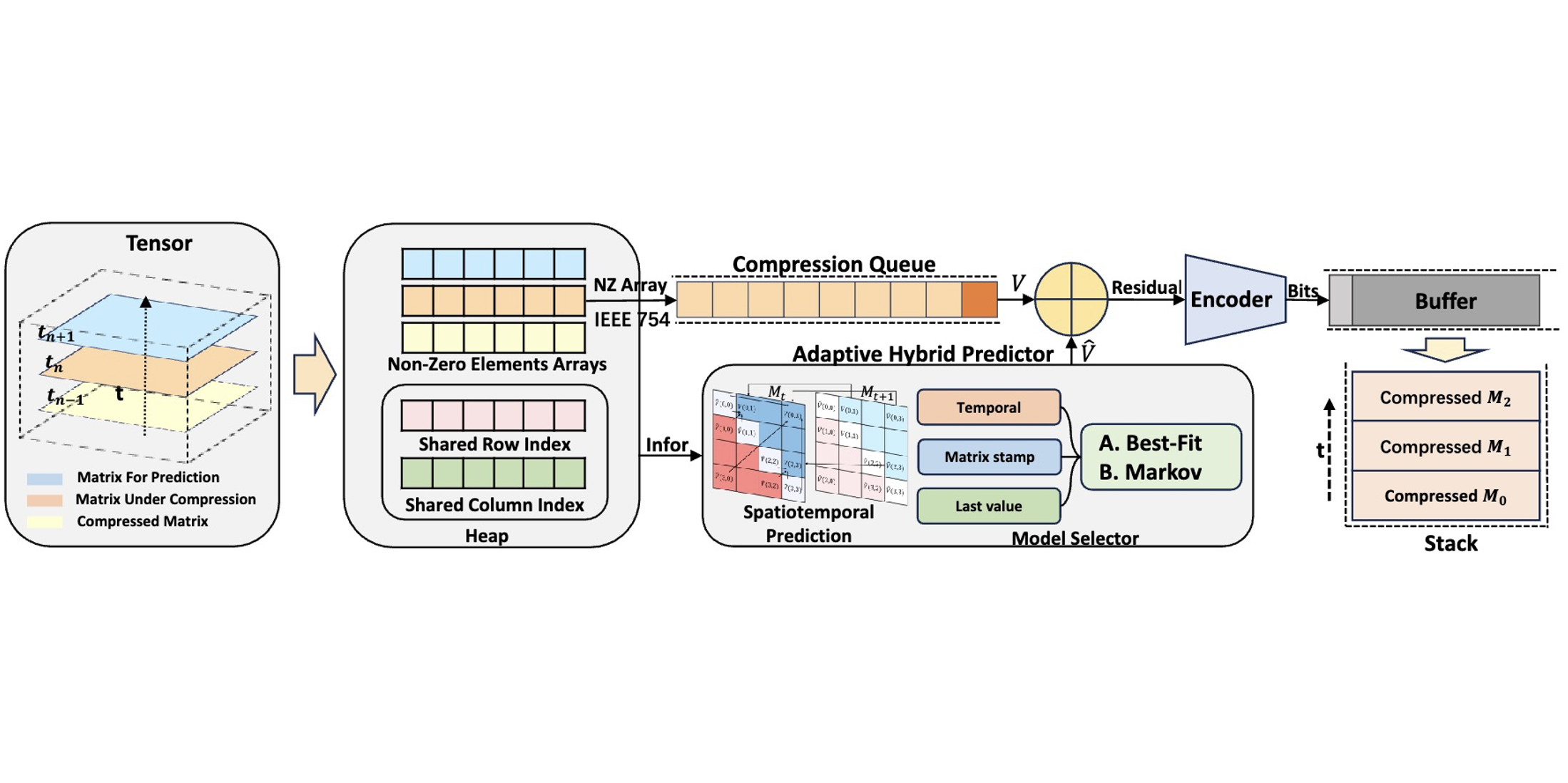
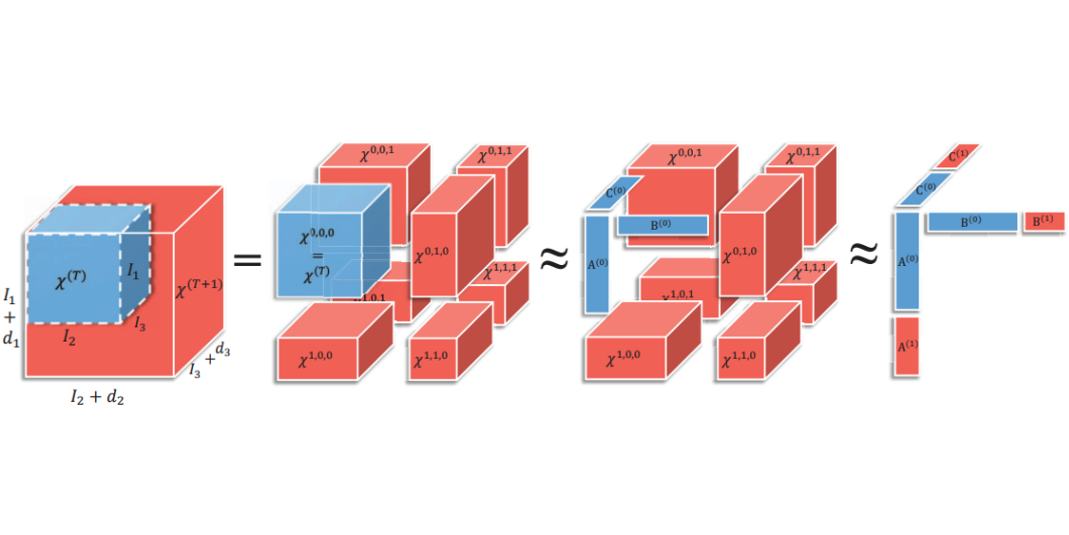
Title: MASC: A Memory-Efficient Adjoint Sensitivity Analysis through Compression Using Novel Spatiotemporal Prediction
Venue: 61st ACM/IEEE Design Automation Conference (DAC '24)
Year: 2024
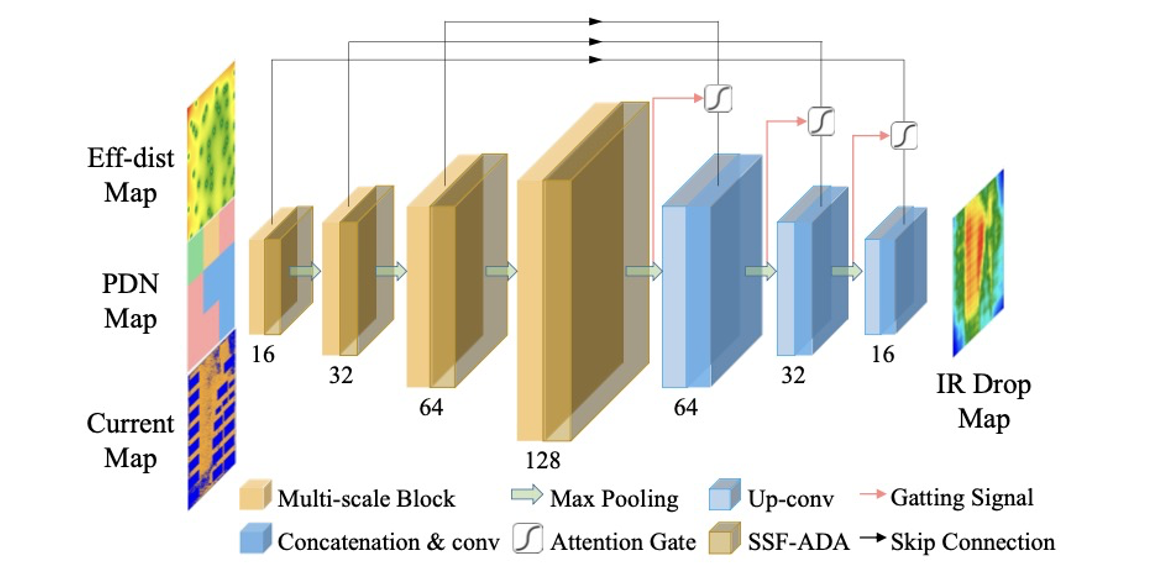
Authors: Mingyue Wang, Yuanqing Cheng, Yage Lin, Kelin Peng, Shunchuan Yang, Zhou Jin, Wei Xing
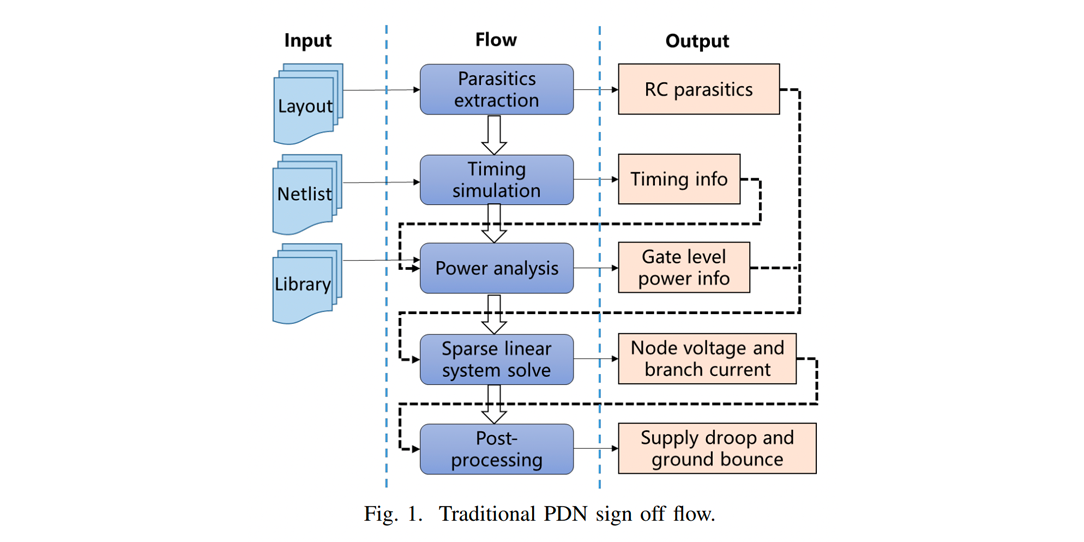
Title: MAUnet: Multiscale Attention U-Net for Effective IR Drop Prediction
Venue: 61st ACM/IEEE Design Automation Conference (DAC '24)
Year: 2024
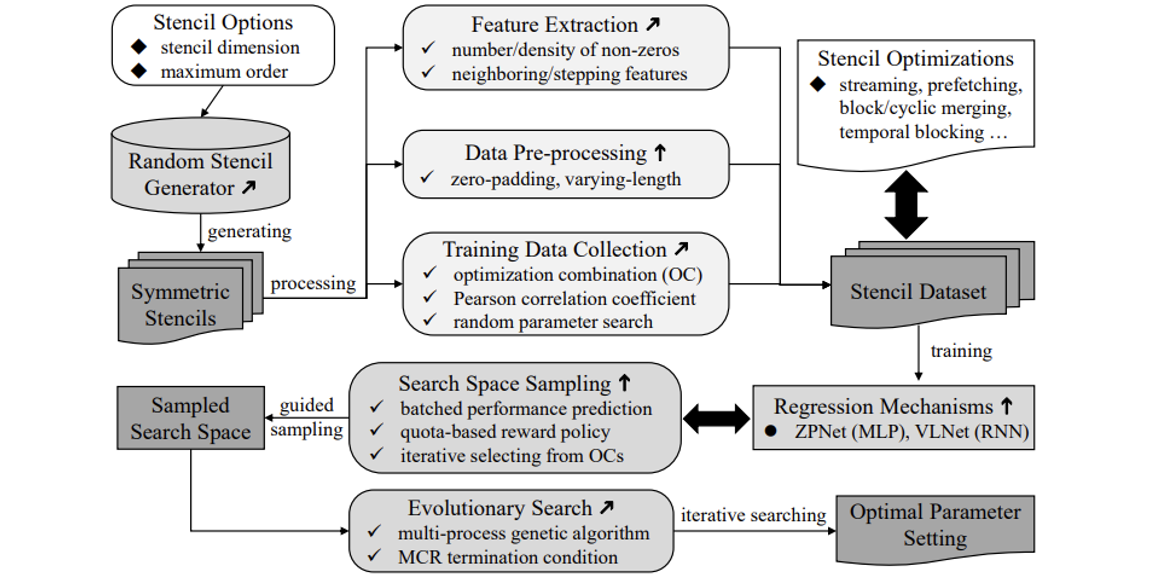
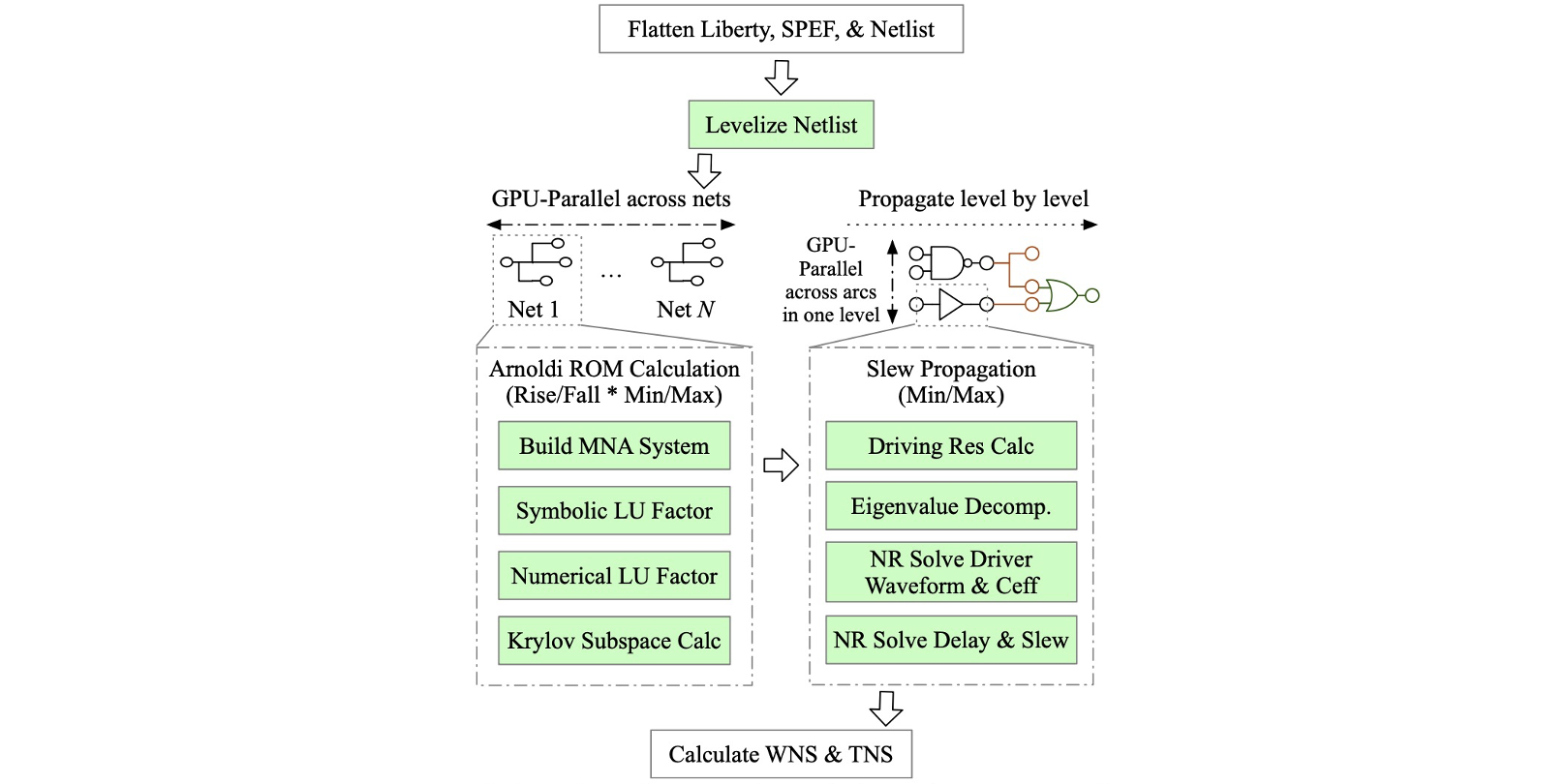
Authors: Zizheng Guo, Tsung-Wei Huang, Zhou Jin, Cheng Zhuo, Yibo Lin, Runsheng Wang, Ru Huang
Title: Heterogeneous Static Timing Analysis with Advanced Delay Calculator
Venue: 21st Design, Automation and Test in Europe Conference (DATE '24)
Year: 2024
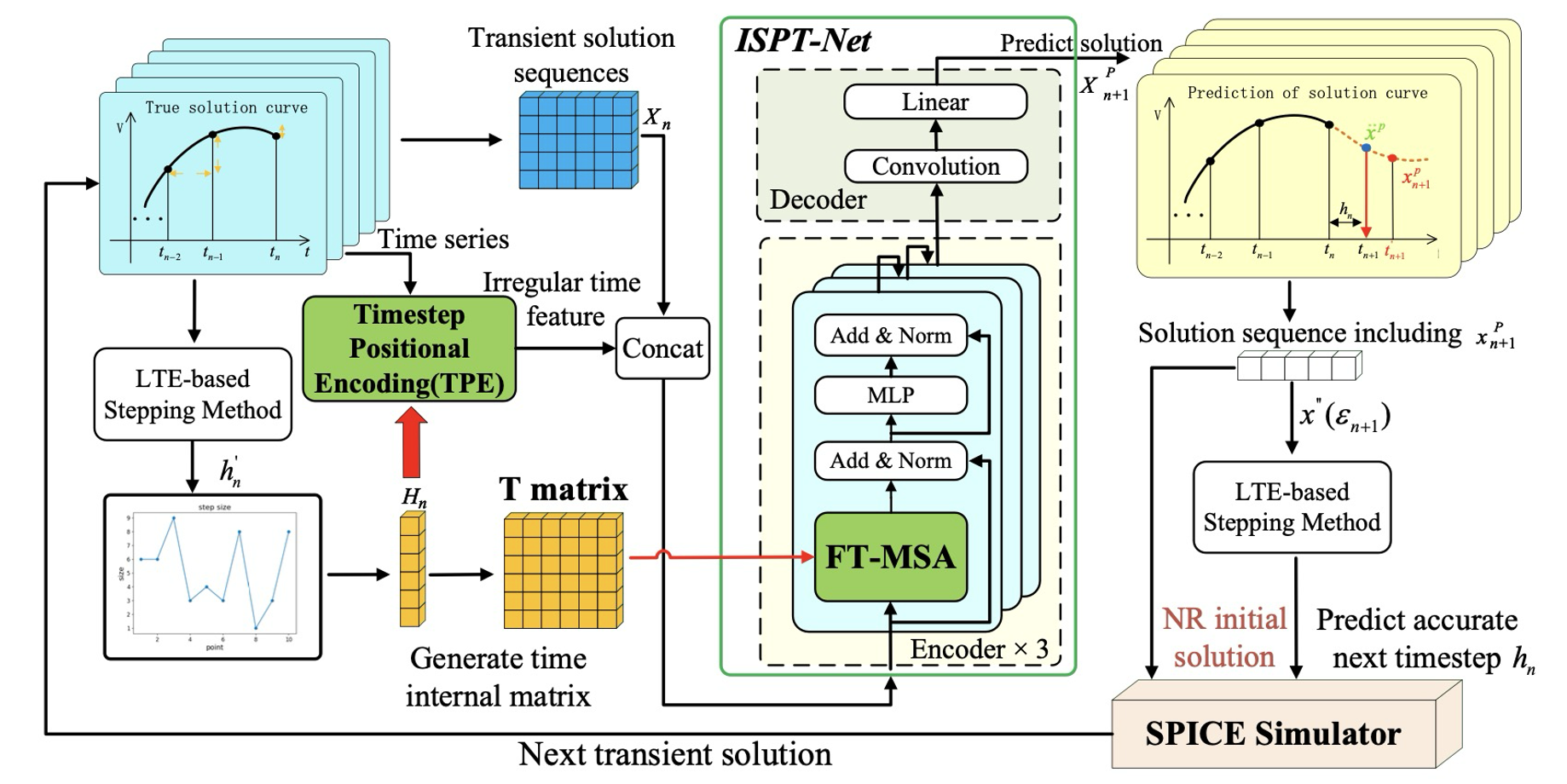
Authors: Yichao Dong, Dan Niu, Zhou Jin, Chuan Zhang, Changyin Sun, Zhenya Zhou
Title: ISPT-Net: A Noval Transient Backward-stepping Reduction Policy by Irregular Sequential PredictionTransformer
Venue: 21st Design, Automation and Test in Europe Conference (DATE '24)
Year: 2024

Authors: Yinuo Bai, Xiaoyu Yang, Yicheng Lu, Dan Niu, Cheng Zhuo, Zhou Jin, Weifeng Liu
Title: Efficient Spectral-Aware Power Supply Noise Analysis for Low-Power Design Verification
Venue: 21st Design, Automation and Test in Europe Conference (DATE '24)
Year: 2024
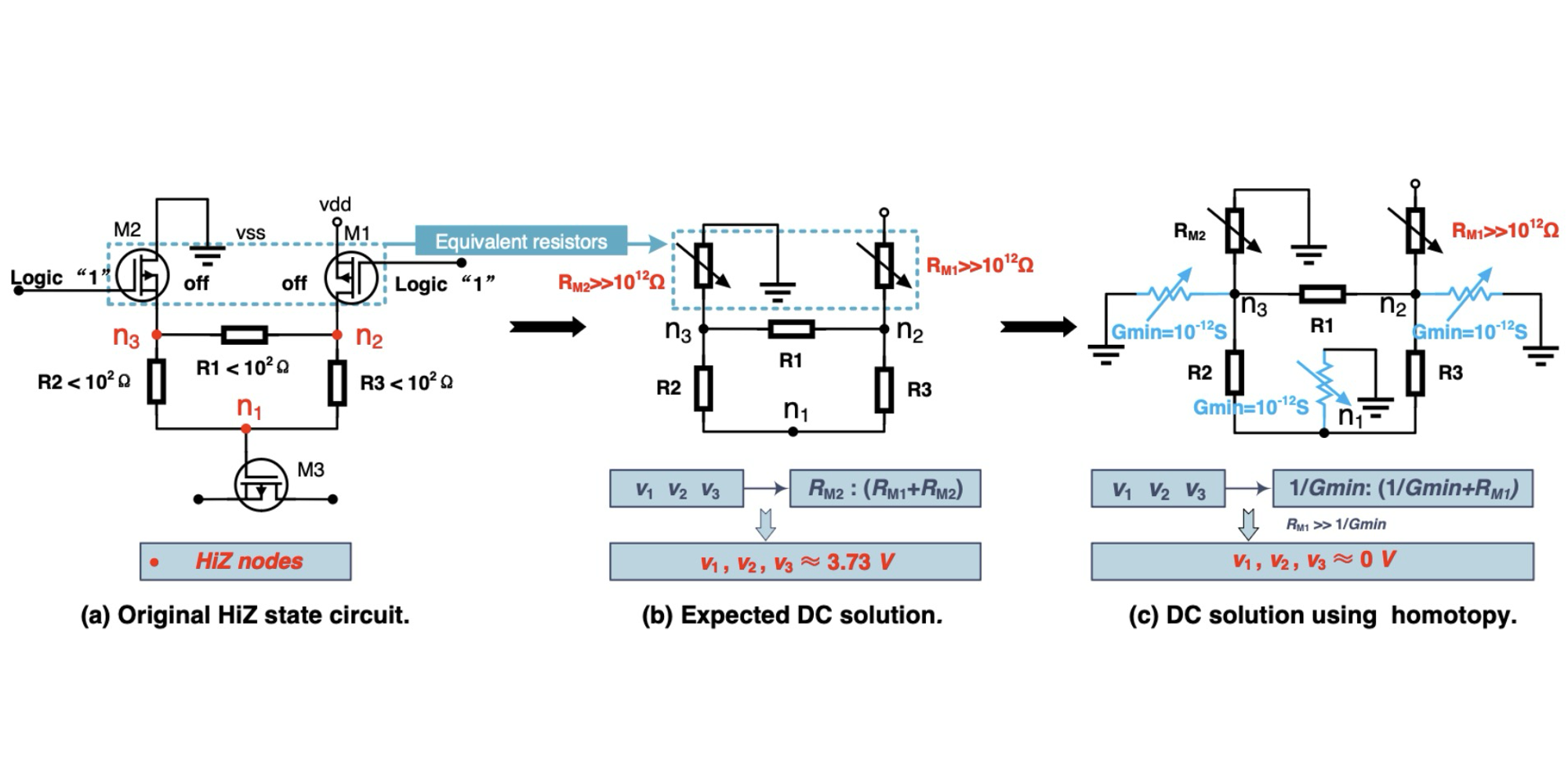
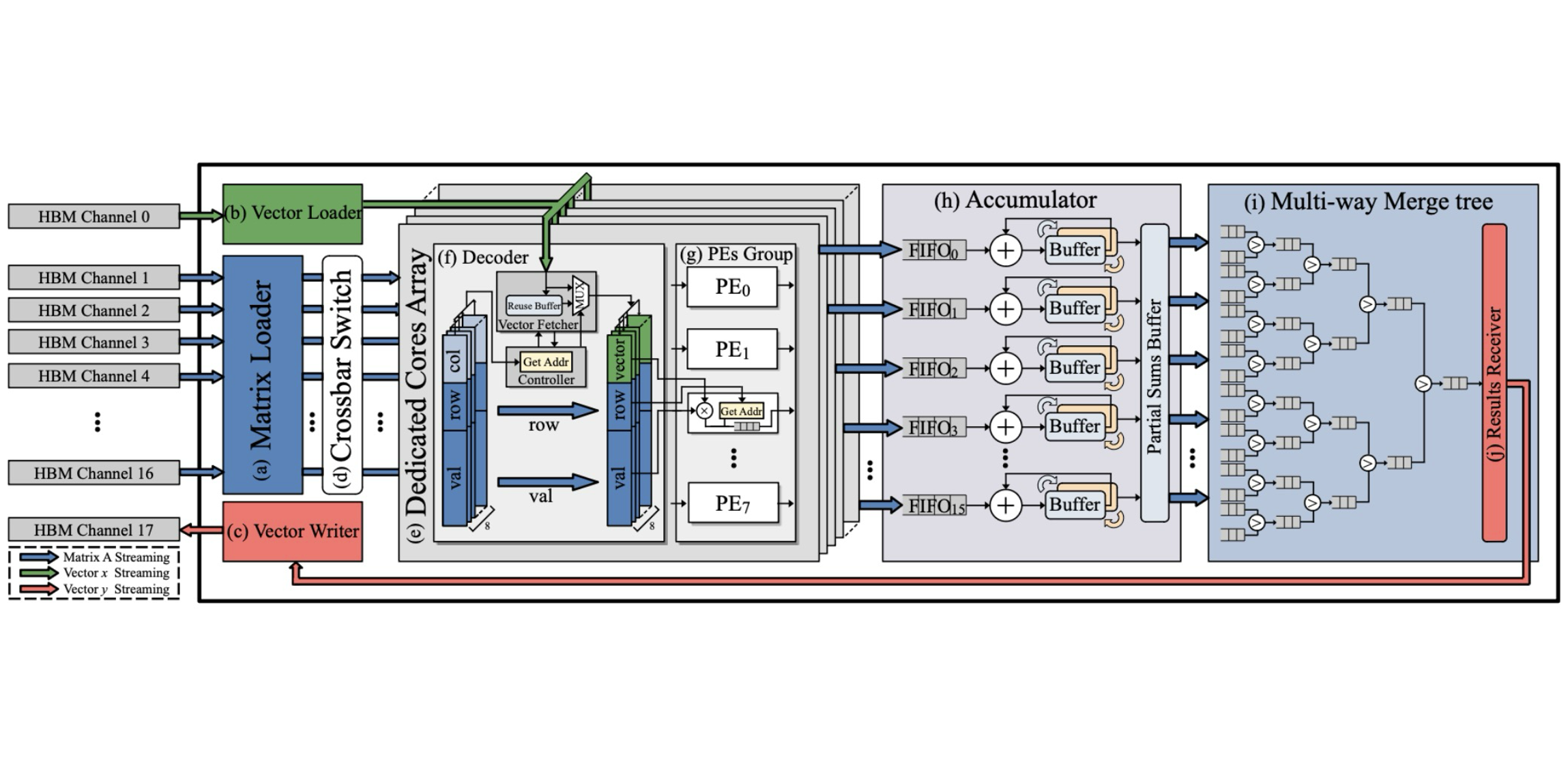
Authors: Enxin Yi, Yiru Duan, Yinuo Bai, Kang Zhao, Zhou Jin, Weifeng Liu
Title: Cuper: Customized Dataflow and Perceptual Decoding for Sparse Matrix-Vector Multiplication on HBM-Equipped FPGAs
Venue: 21st Design, Automation and Test in Europe Conference (DATE '24)
Year: 2024
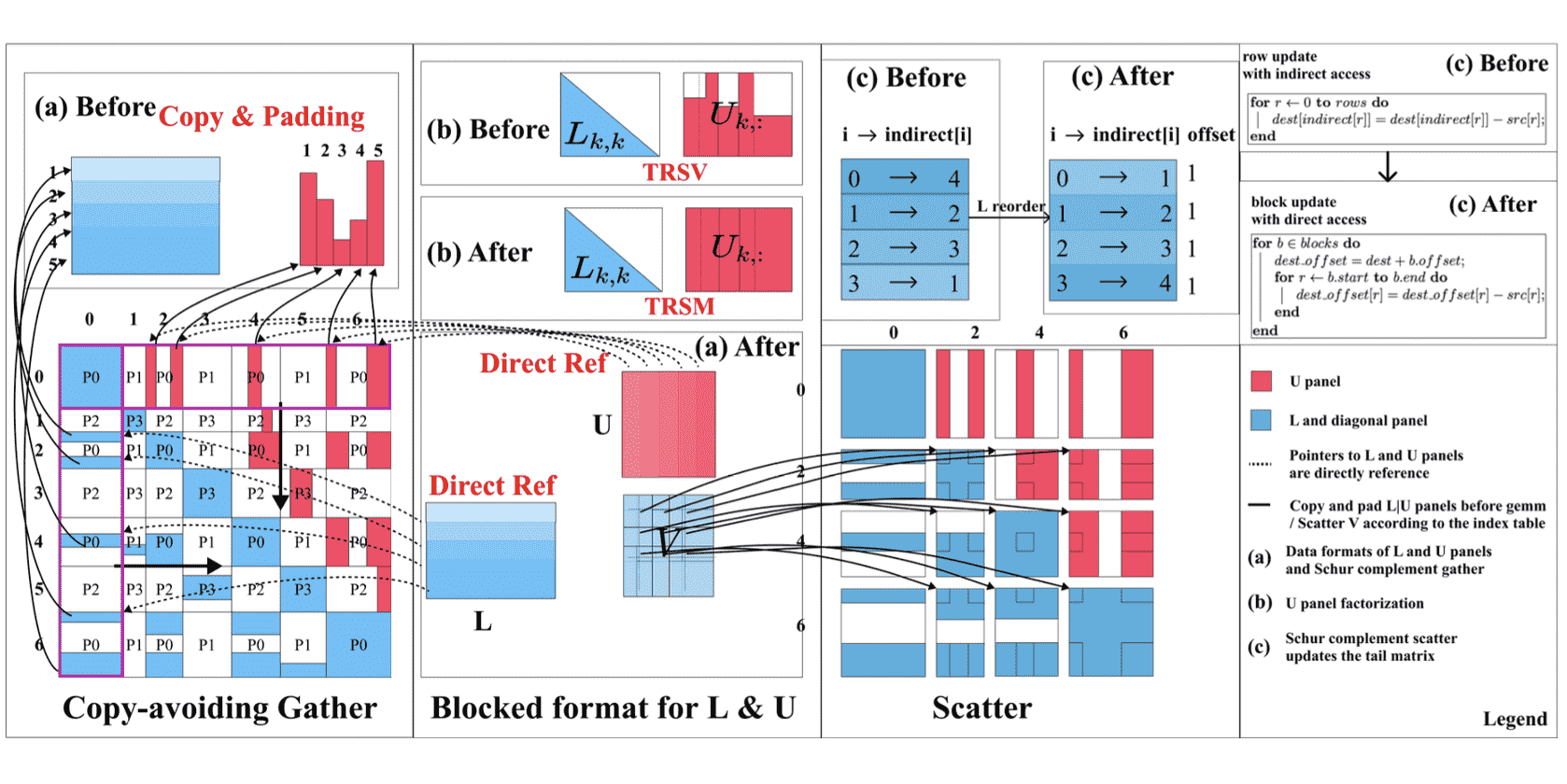
Authors: Guofeng Feng, Hongyu Wang, Zhuoqiang Guo, Mingzhen Li, Tong Zhao, Zhou Jin, Weile Jia, Guangming Tan, Ninghui Sun
Title: Accelerating Large-scale Sparse LU Factorization for RF Circuit Simulation
Venue: 30th International European Conference on Parallel and Distributed Computing (Euro-Par '24)
Year: 2024
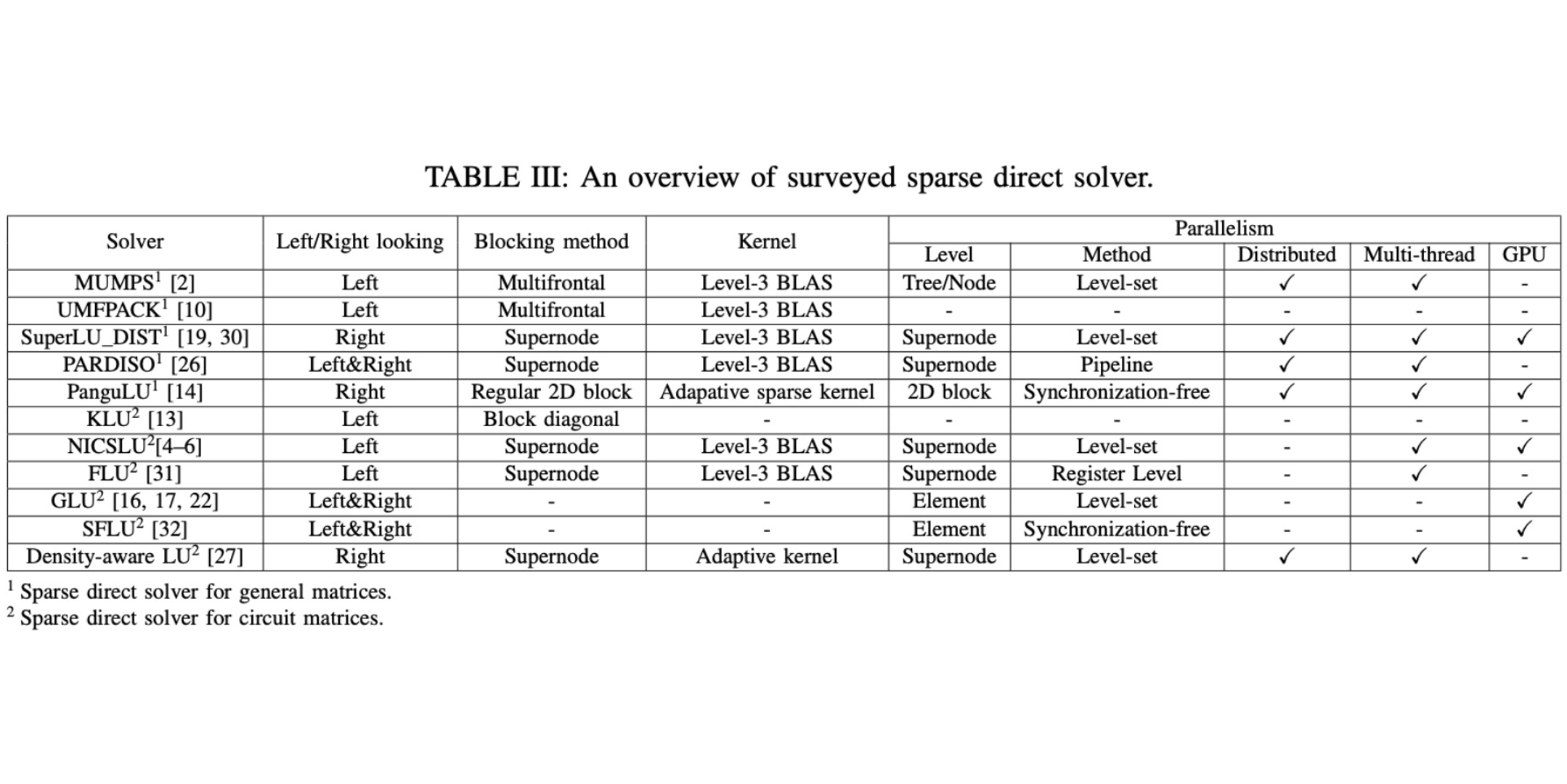
Authors: Zhou Jin, Wenhao Li, Yinuo Bai, Tengcheng Wang, Yicheng Lu, Weifeng Liu
Title: Machine Learning and GPU Accelerated Sparse Linear Solvers for Transistor-Level Circuit Simulation: A Perspective Survey (Invited Paper)
Venue: 29th ACM/IEEE Asia and South Pacific Design Automation Conference (ASP-DAC '24)
Year: 2024
2023
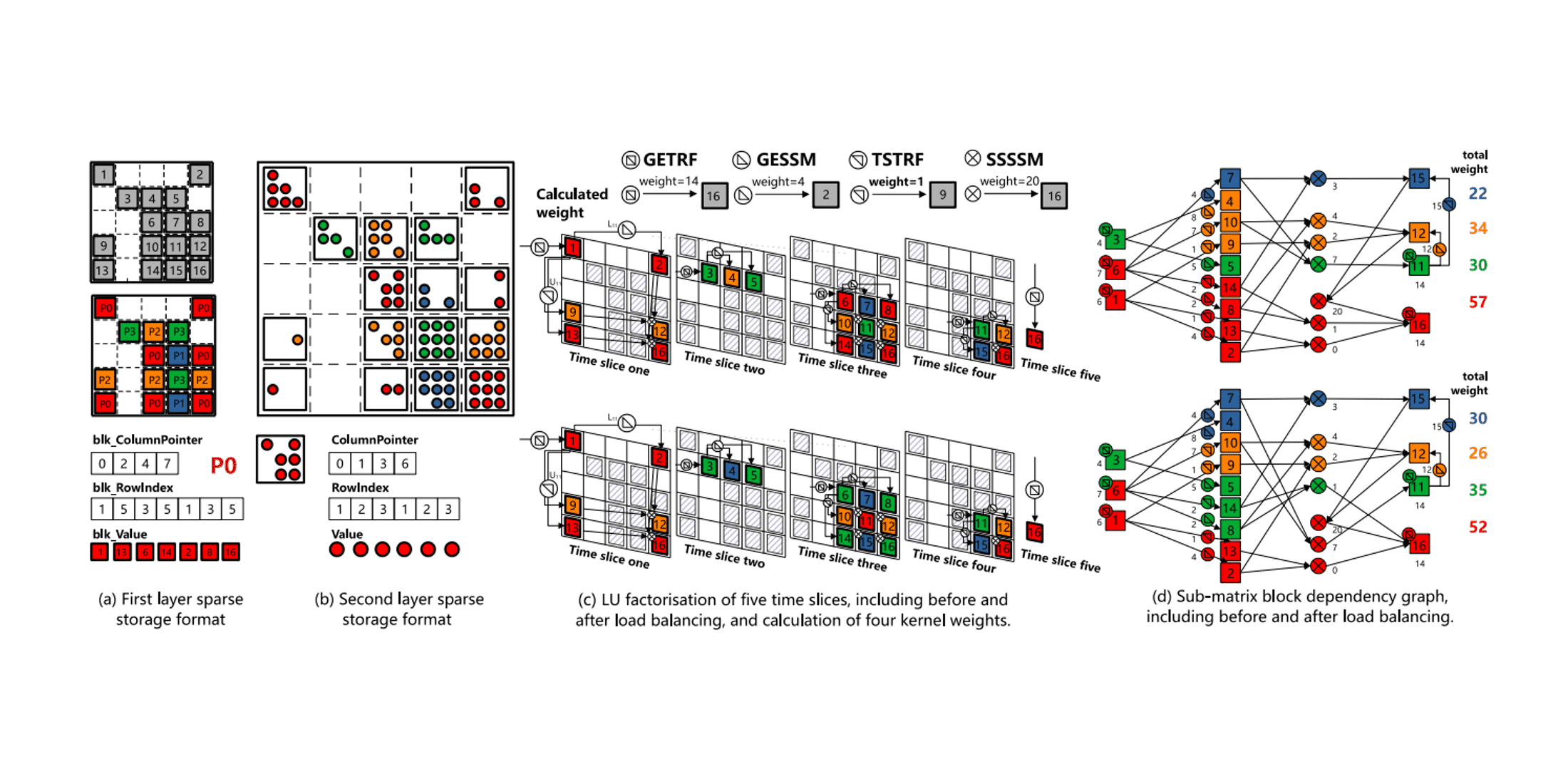
Authors: Xu Fu, Bingbin Zhang, Tengcheng Wang, Wenhao Li, Yuechen Lu, Enxin Yi, Jianqi Zhao, Xiaohan Geng, Fangying Li, Jingwen Zhang, Zhou Jin, Weifeng Liu
Title: PanguLU: A Scalable Regular Two-Dimensional Block-Cyclic Sparse Direct Solver on Distributed Heterogeneous Systems
Award: Best Paper Award
Venue: 36th International Conference for High Performance Computing, Networking, Storage, and Analysis (SC '23)
Year: 2023
Authors: Yuechen Lu, Weifeng Liu
Title: DASP: Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multiplication
Venue: 36th International Conference for High Performance Computing, Networking, Storage, and Analysis (SC '23)
Year: 2023
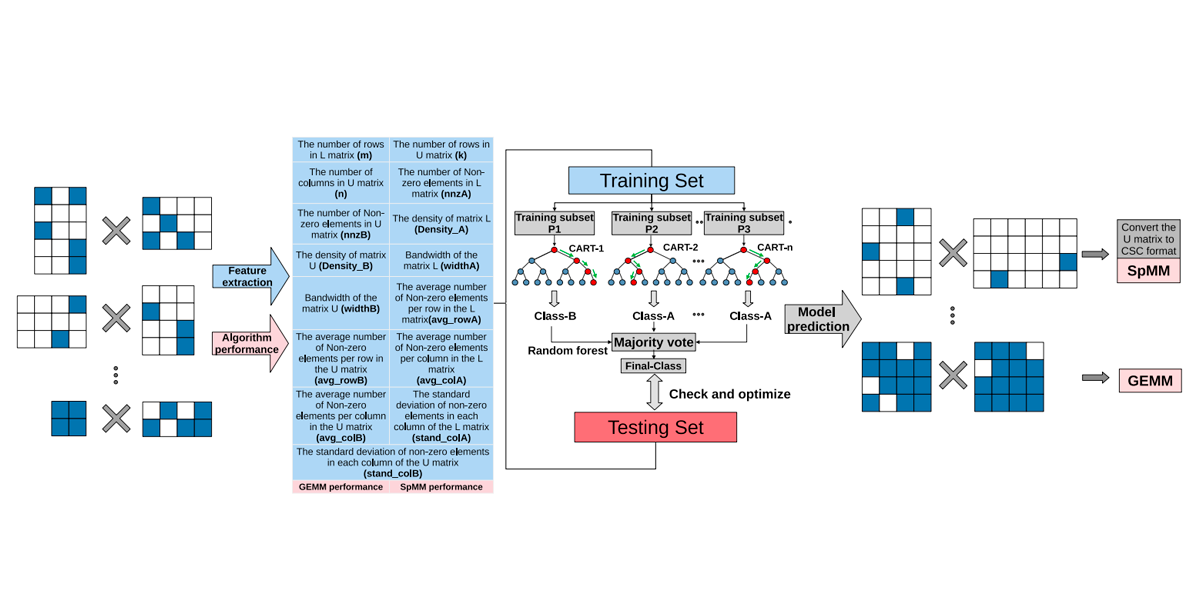
Authors: Tengcheng Wang, Wenhao Li, Haojie Pei, Yuying Sun, Zhou Jin, Weifeng Liu
Title: Accelerating Sparse LU Factorization with Density-Aware Adaptive Matrix Multiplication for Circuit Simulation
Venue: 60th ACM/IEEE Design Automation Conference (DAC '23)
Year: 2023
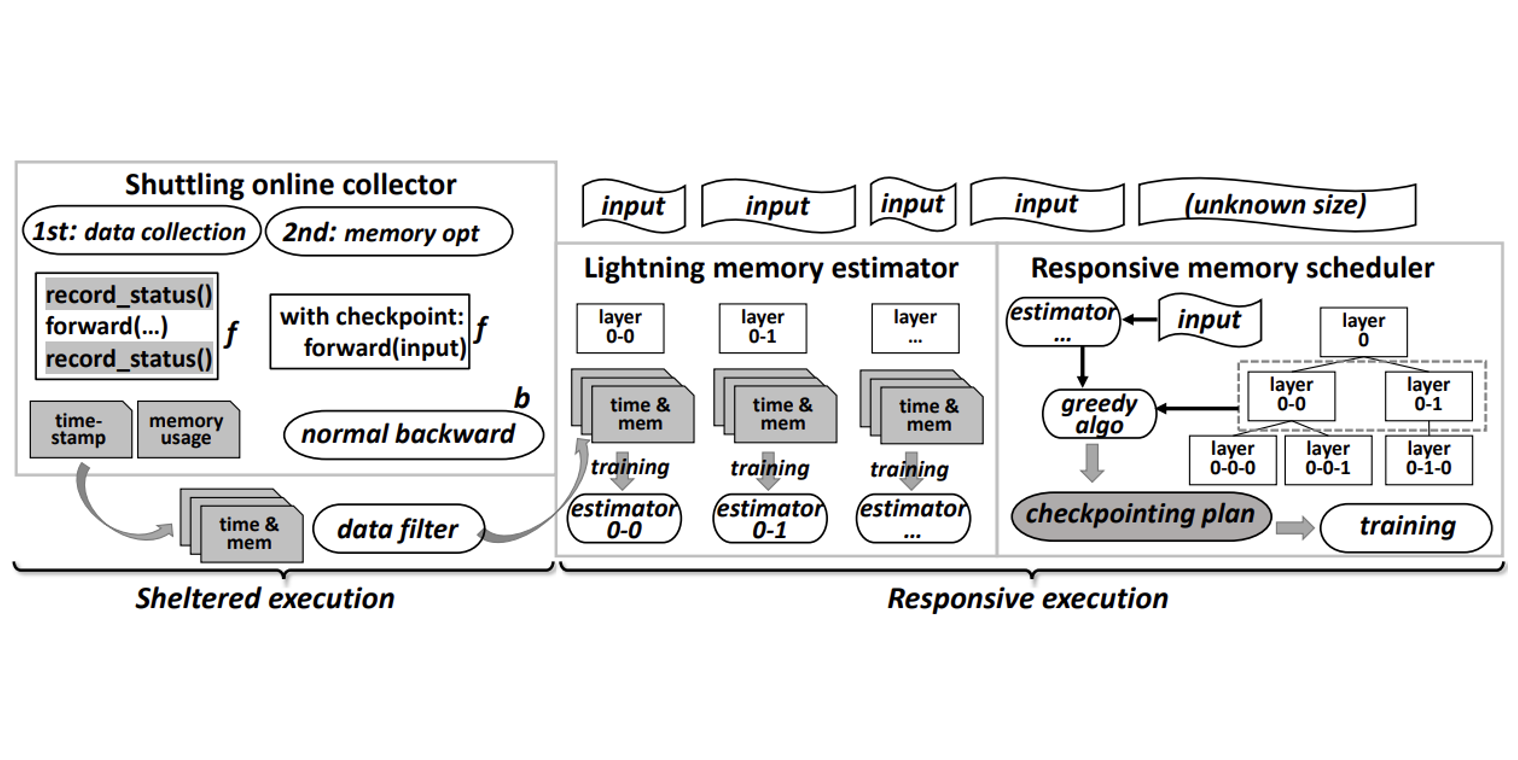
Authors: Jianjin Liao, Mingzhen Li, Hailong Yang, Qingxiao Sun, Biao Sun, Jiwei Hao, Tianyu Feng, Fengwei Yu, Shengdong Chen, Ye Tao, Zicheng Zhang, Zhongzhi Luan, Depei Qian
Title: Exploiting Input Tensor Dynamics in Activation Checkpointing for Efficient Training on GPU
Venue: 37th IEEE International Parallel and Distributed Processing Symposium (IPDPS '23)
Year: 2023
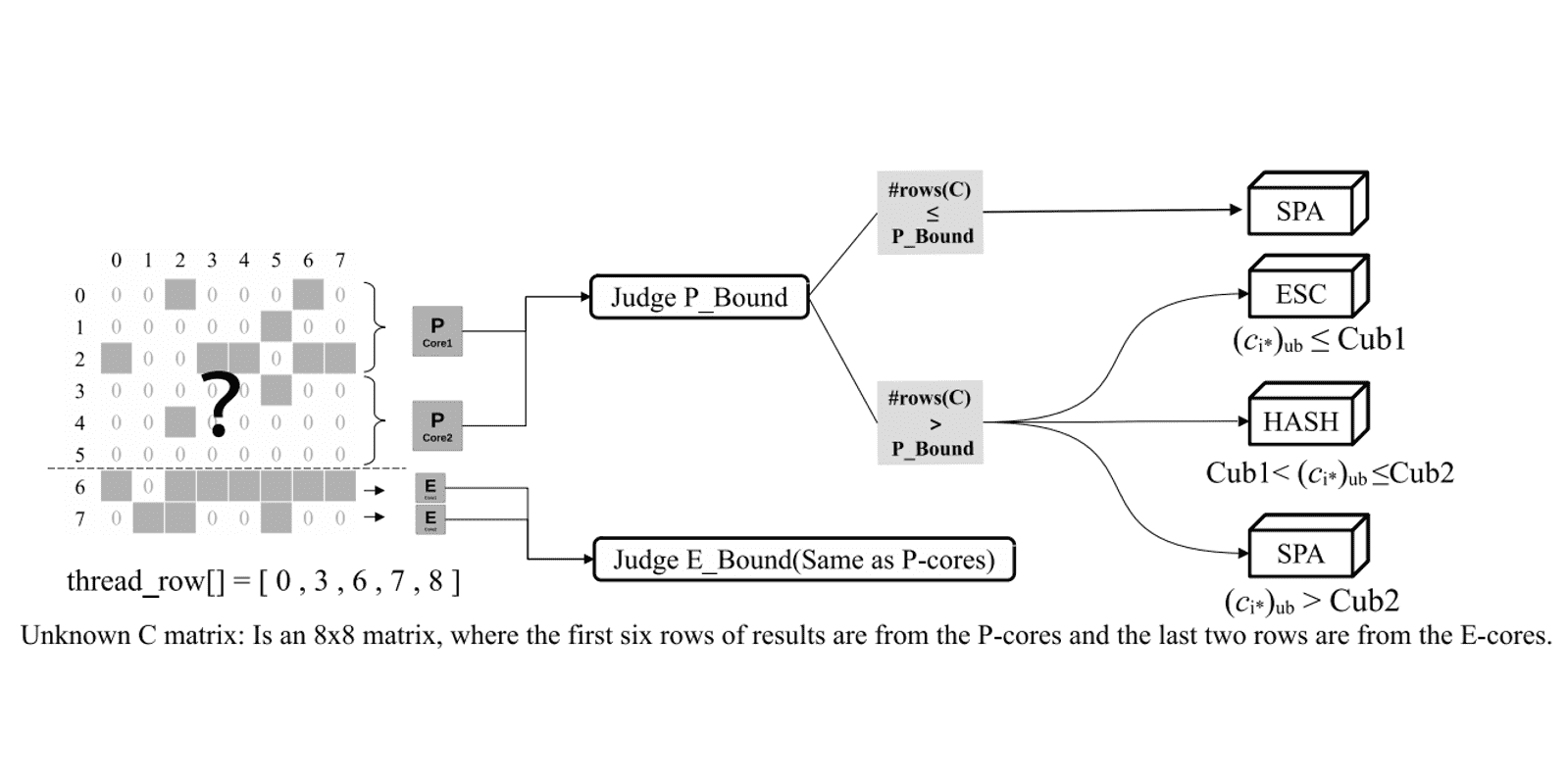
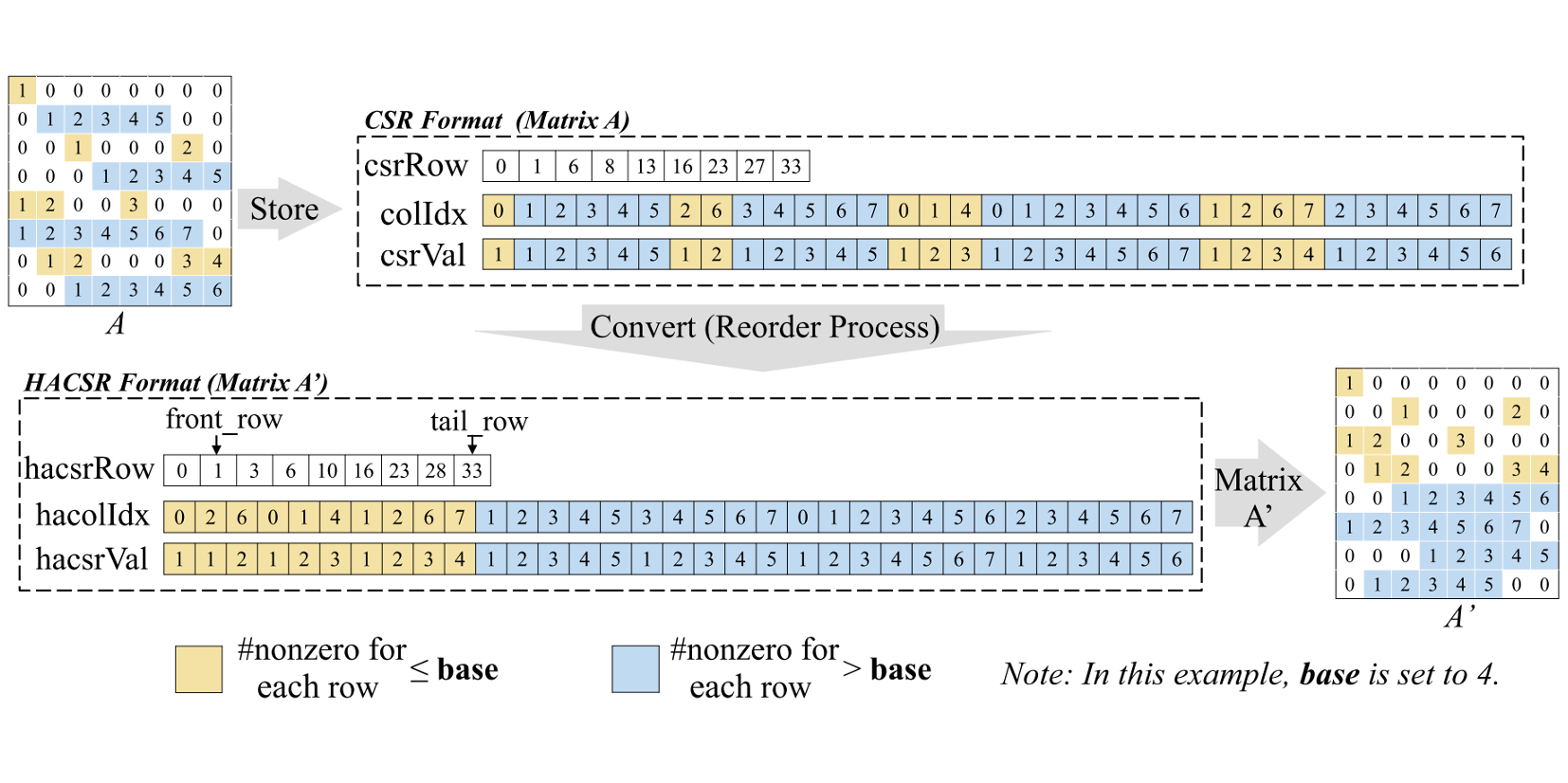
Authors: Wenxuan Li, Helin Cheng, Zhengyang Lu, Yuechen Lu, Weifeng Liu
Title: HASpMV: Heterogeneity-Aware Sparse Matrix-Vector Multiplication on Modern Asymmetric Multicore Processors
Venue: 25th IEEE International Conference on Cluster Computing (CLUSTER '23)
Year: 2023
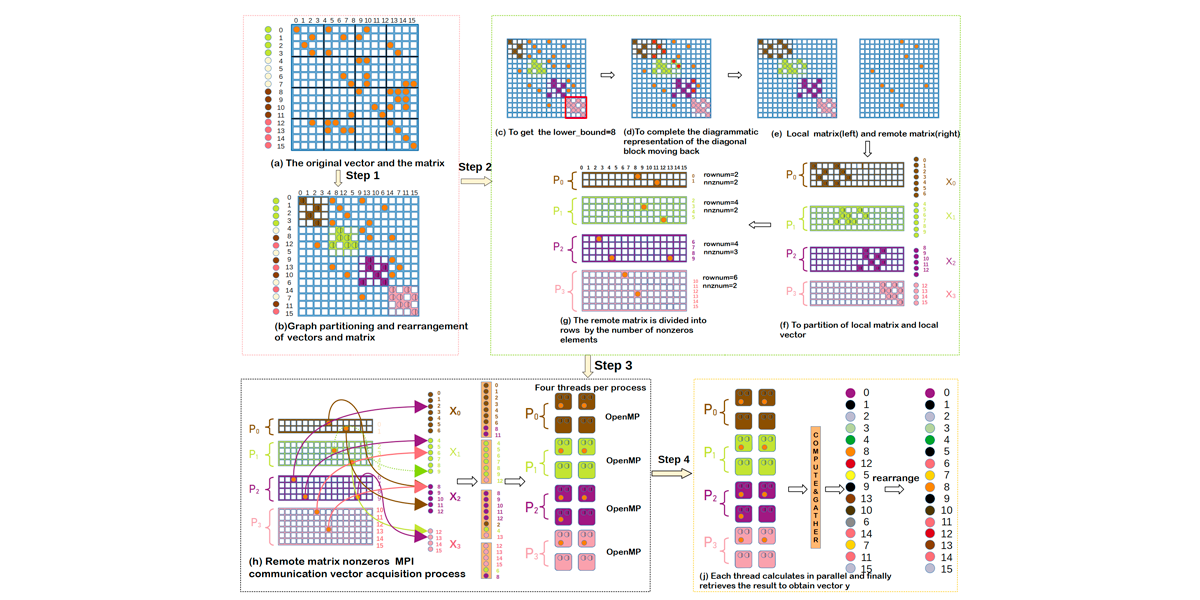
Authors: Hongli Mi, Xiangrui Yu, Xiaosong Yu, Shuangyuan Wu, Weifeng Liu
Title: Balancing Computation and Communication in Distributed Sparse Matrix-Vector Multiplication
Venue: 23rd IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID '23)
Year: 2023
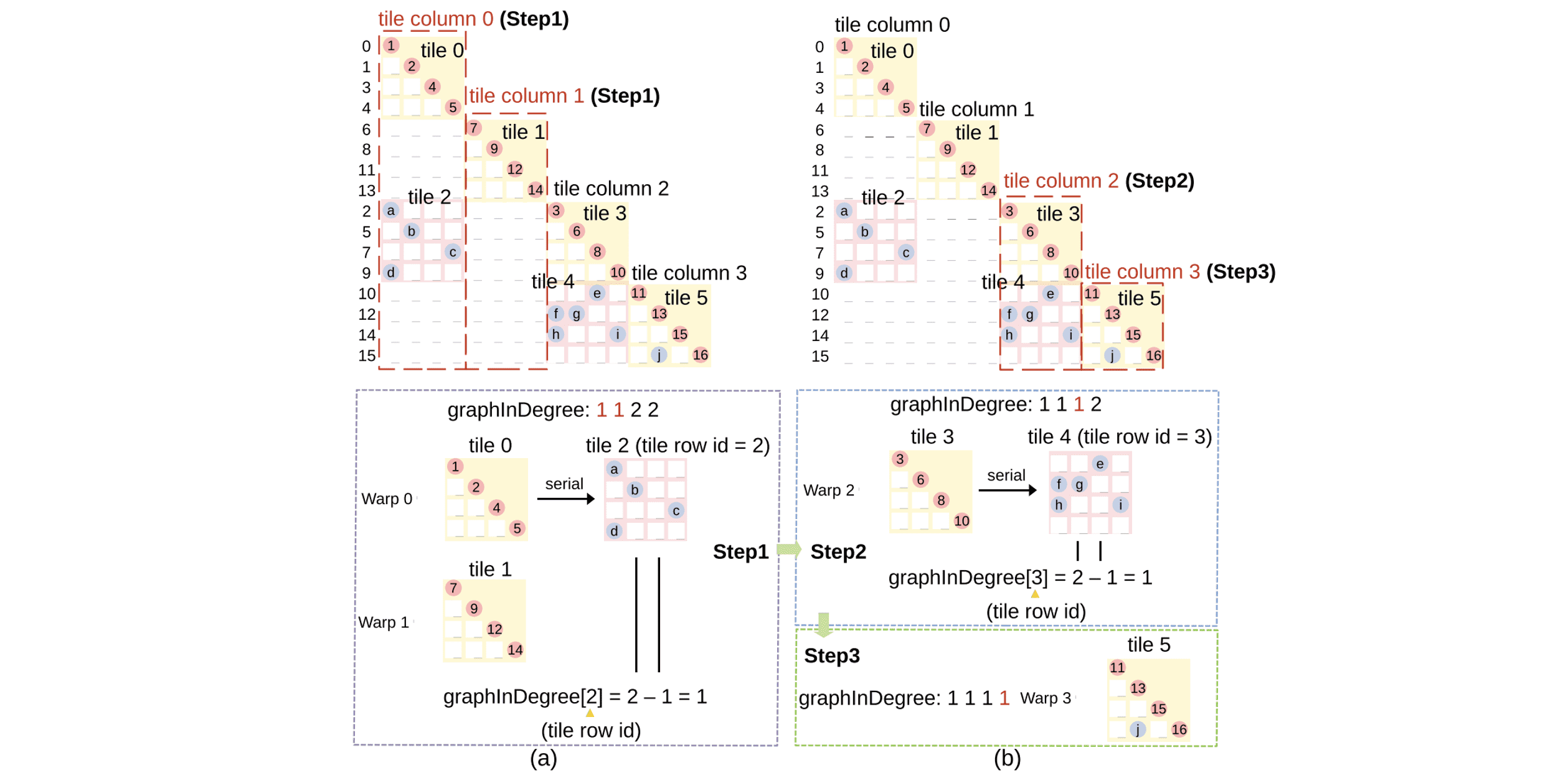
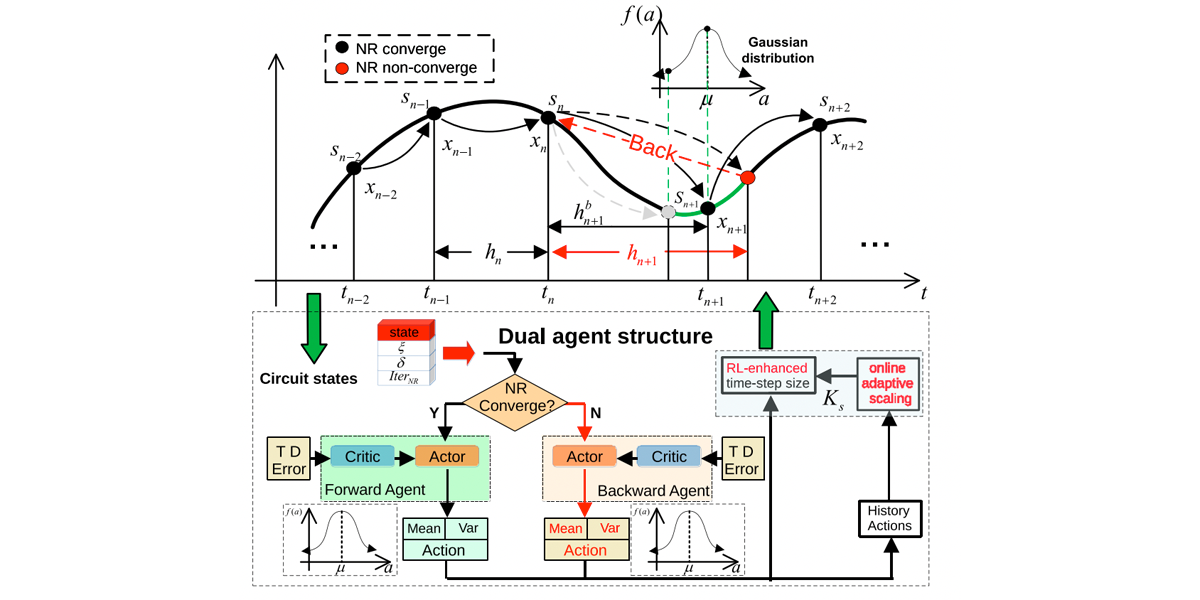
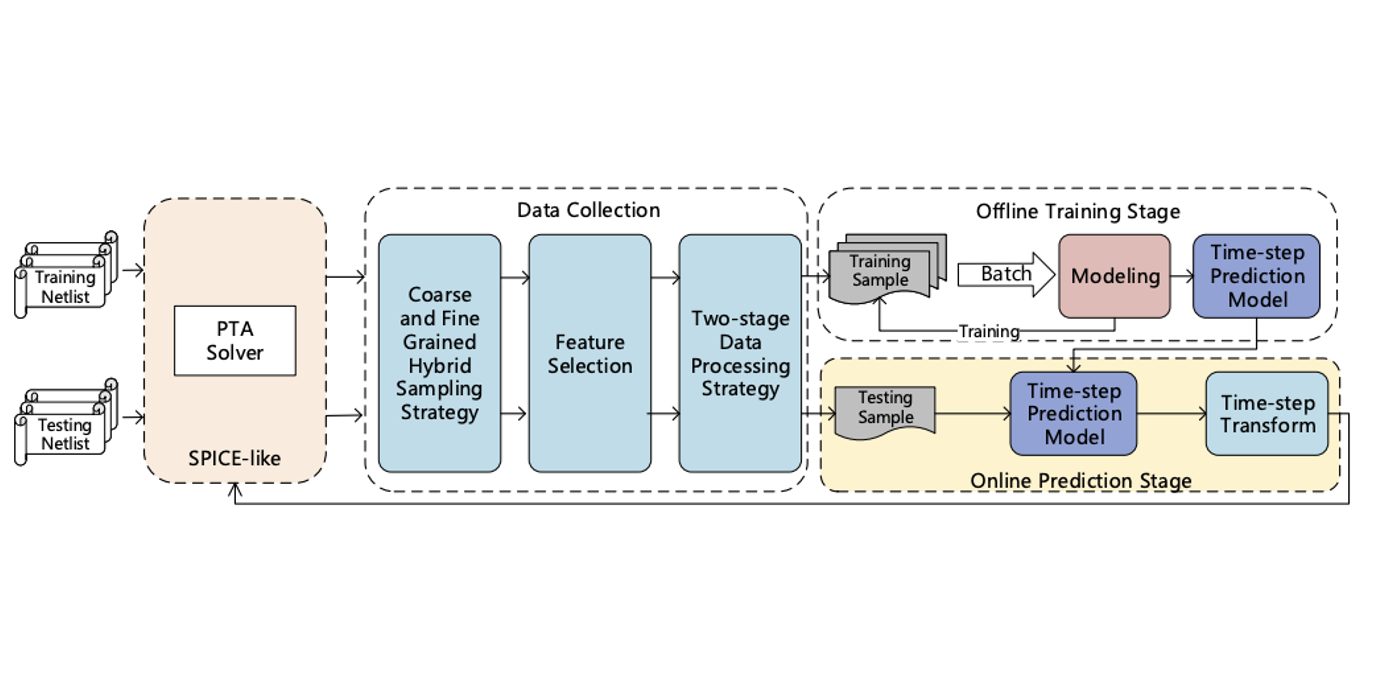
Authors: Xiaru Zha, Haojie Pei, Dan Niu, Xiao Wu, Zhou Jin
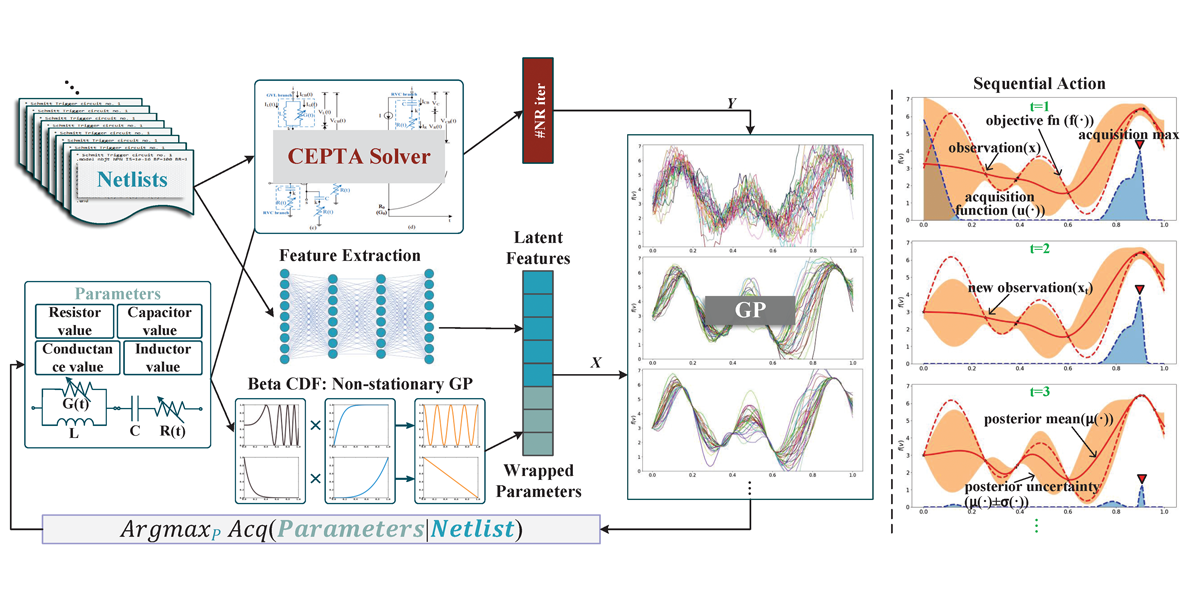
Title: Deep Learning Enhanced Time-step Control in Pseudo Transient Analysis for Efficient Nonlinear DC Simulation
Award: Honorable Paper Award
Venue: 1st IEEE/ACM International Symposium of Electronics Design Automation (ISEDA '23)
Year: 2023
2022
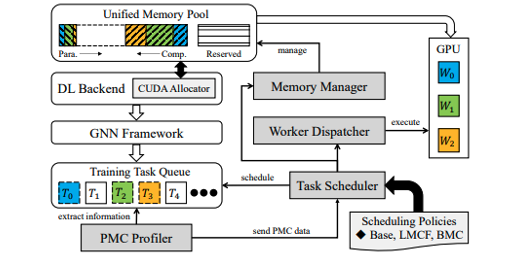
Authors: Qingxiao Sun, Yi Liu, Hailong Yang, Ruizhe Zhang, Ming Dun, Mingzhen Li, Xiaoyan Liu, Wencong Xiao, Yong Li, Zhongzhi Luan, Depei Qian
Title: CoGNN: Efficient Scheduling for Concurrent GNN Training on GPUs
Venue: 35th International Conference for High Performance Computing, Networking, Storage, and Analysis (SC '22)
Year: 2022
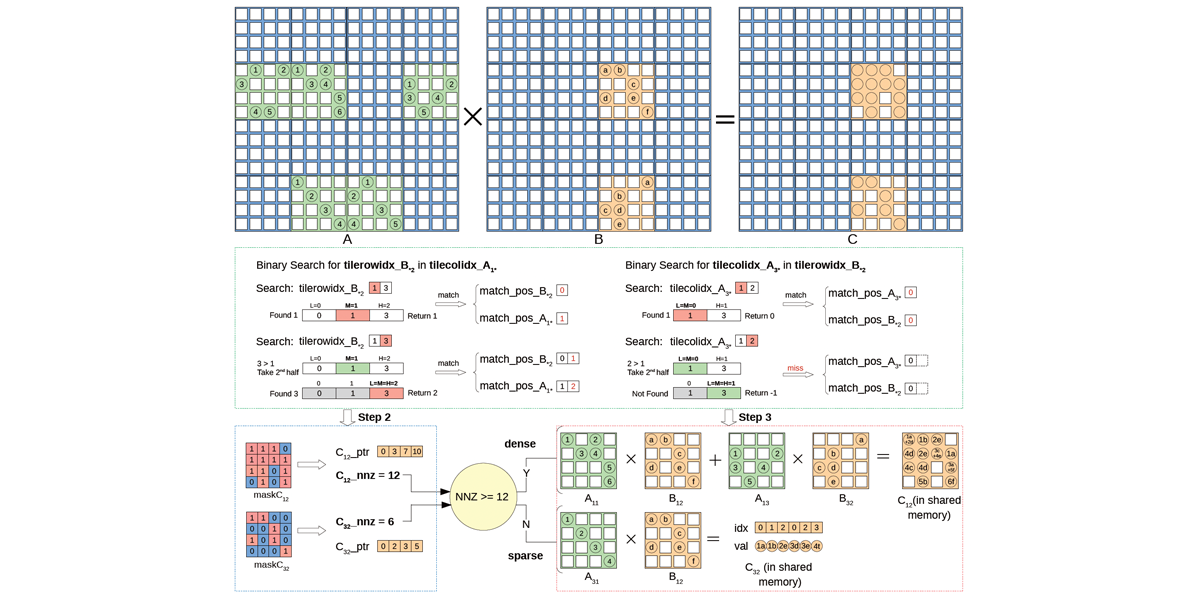
Authors: Yuyao Niu, Zhengyang Lu, Haonan Ji, Shuhui Song, Zhou Jin, Weifeng Liu
Title: TileSpGEMM: A Tiled Algorithm for Parallel Sparse General Matrix-Matrix Multiplication on GPUs
Venue: 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP '22)
Year: 2022
[PDF] [Slides] [DOI] [Bibtex] [Code]
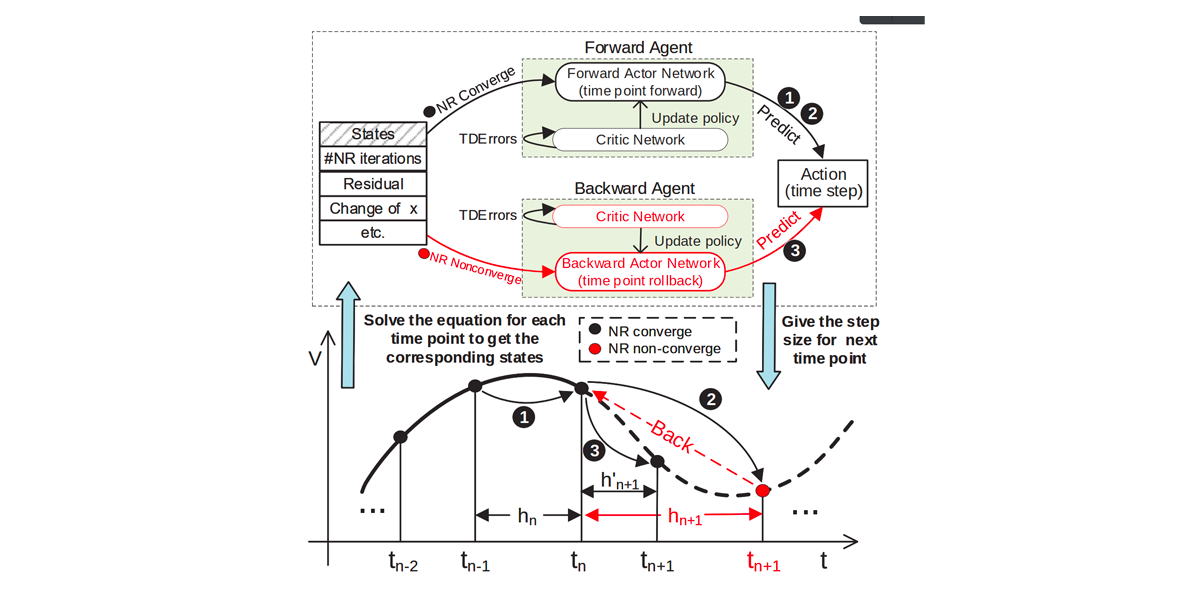
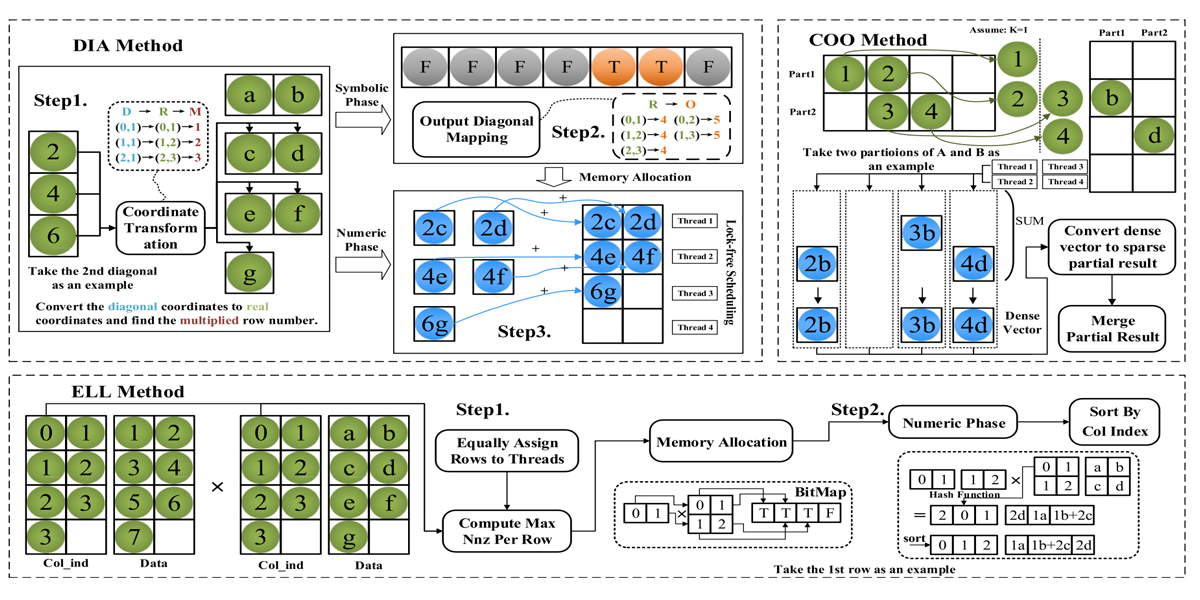
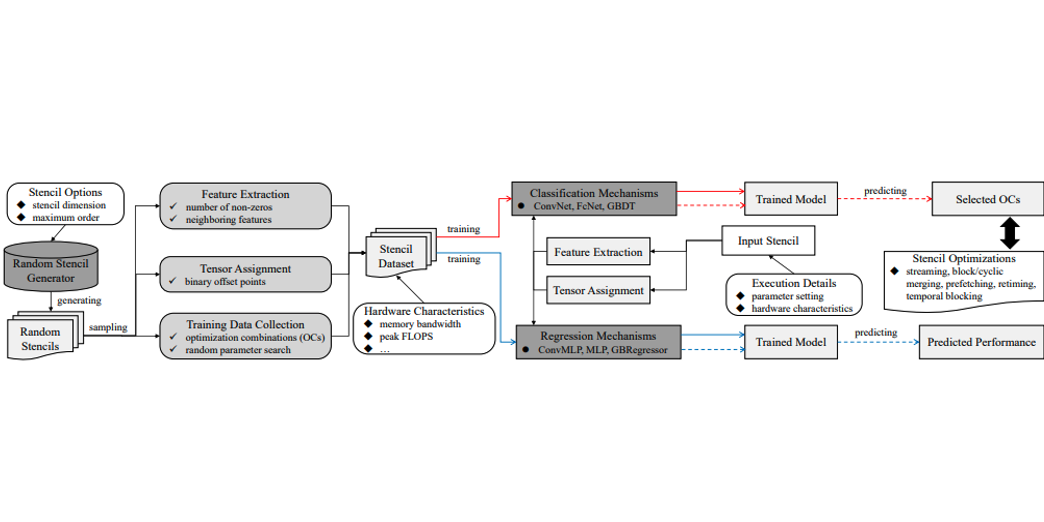
Authors: Qingxiao Sun, Yi Liu, Hailong Yang, Zhonghui Jiang, Zhongzhi Luan, Depei Qian
Title: StencilMART: Predicting Optimization Selection for Stencil Computations Across GPUs
Venue: 36th IEEE International Parallel and Distributed Processing Symposium (IPDPS '22)
Year: 2022
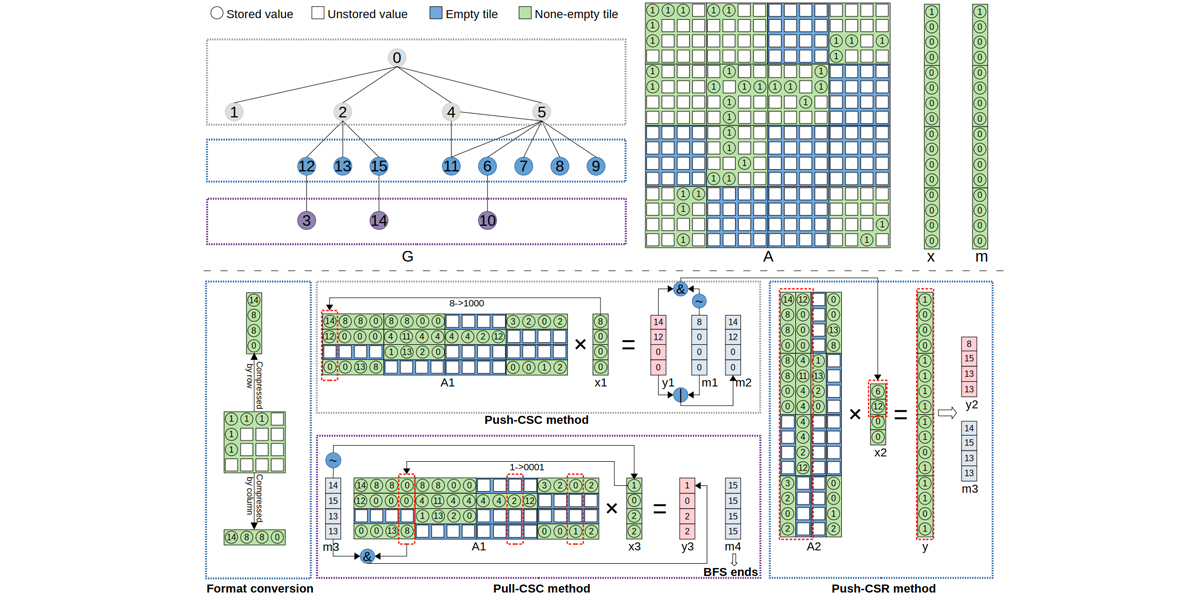
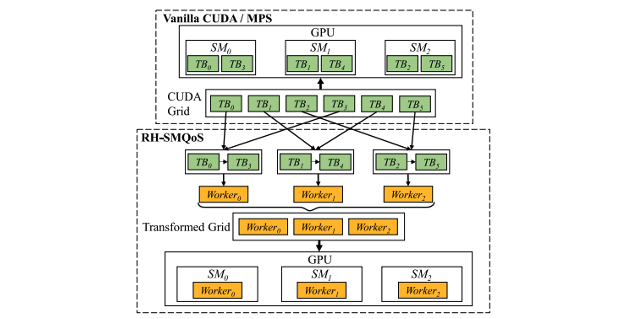
Authors: Jiwei Hao, Hailong Yang, Qingxiao Sun, Huaitao Zhang, Zhongzhi Luan, Depei Qian
Title: Towards Optimized Streaming Tensor Completion on Multiple GPUs
Venue: 24th IEEE International Conference on High Performance Computing and Communications (HPCC '22)
Year: 2022
2021

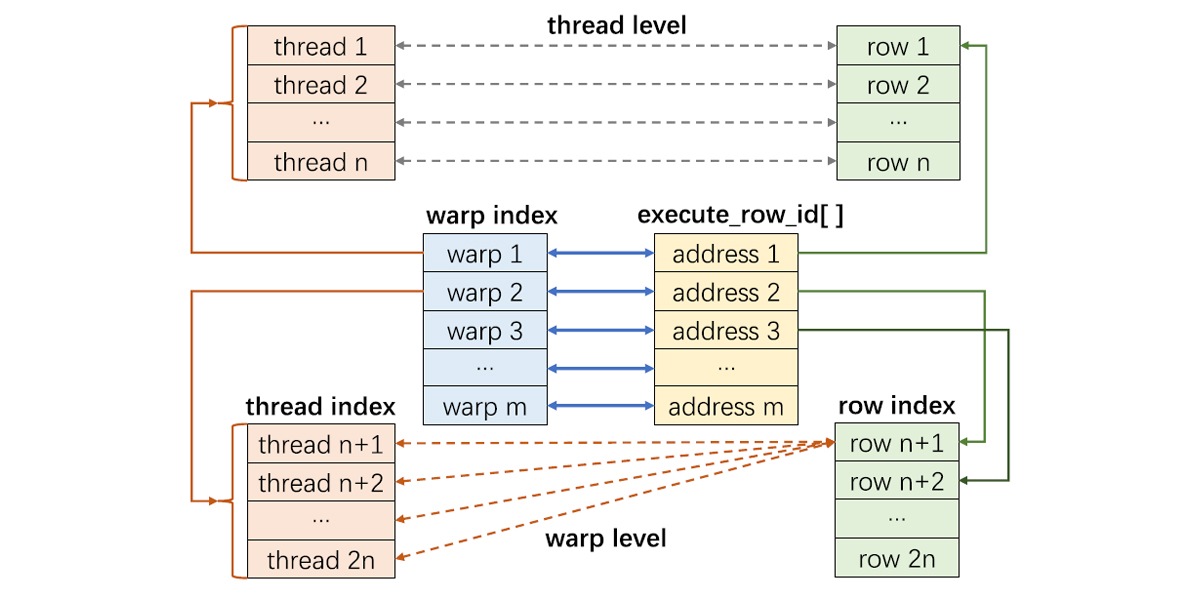
Authors: Feng Zhang, Jiya Su, Weifeng Liu, Bingsheng He, Ruofan Wu, Xiaoyong Du, Rujia Wang
Title: YuenyeungSpTRSV: A Thread-Level and Warp-Level Fusion Synchronization-Free Sparse Triangular Solve
Venue: IEEE Transactions on Parallel and Distributed Systems (TPDS)
Year: 2021
[PDF] [Slides] [DOI] [Bibtex] [Code]
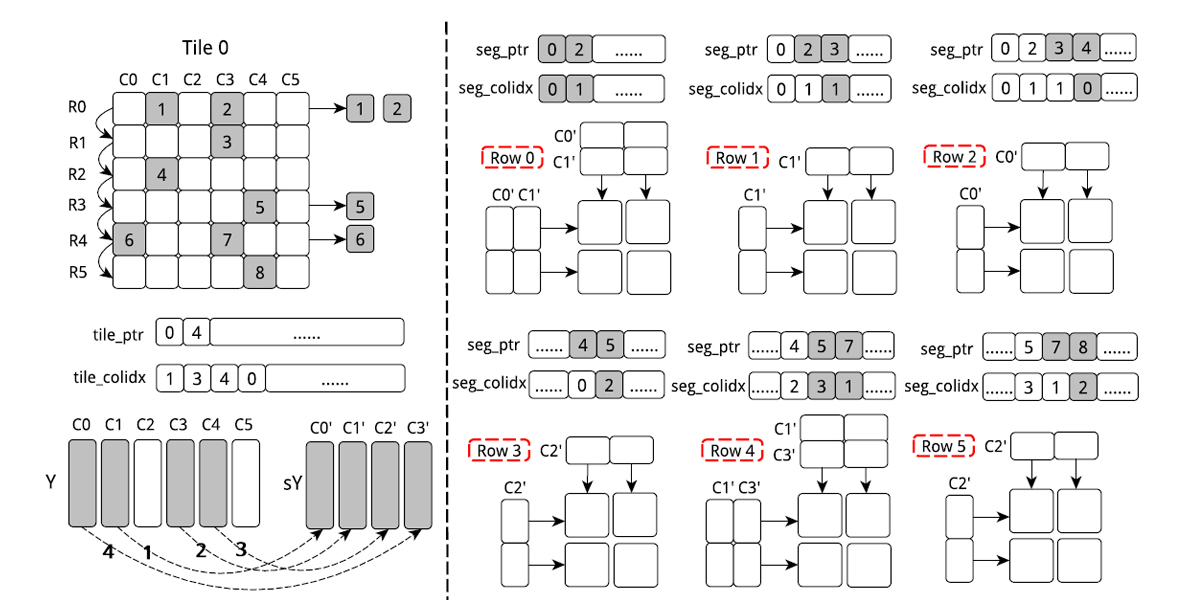
Authors: Qingxiao Sun, Yi Liu, Hailong Yang, Ming Dun, Zhongzhi Luan, Lin Gan, Guangwen Yang, Depei Qian
Title: Input-Aware Sparse Tensor Storage Format Selection for Optimizing MTTKRP
Award: IEEE Computer's "Spotlight on Transactions" column
Venue: IEEE Transactions on Computers (TC)
Year: 2021
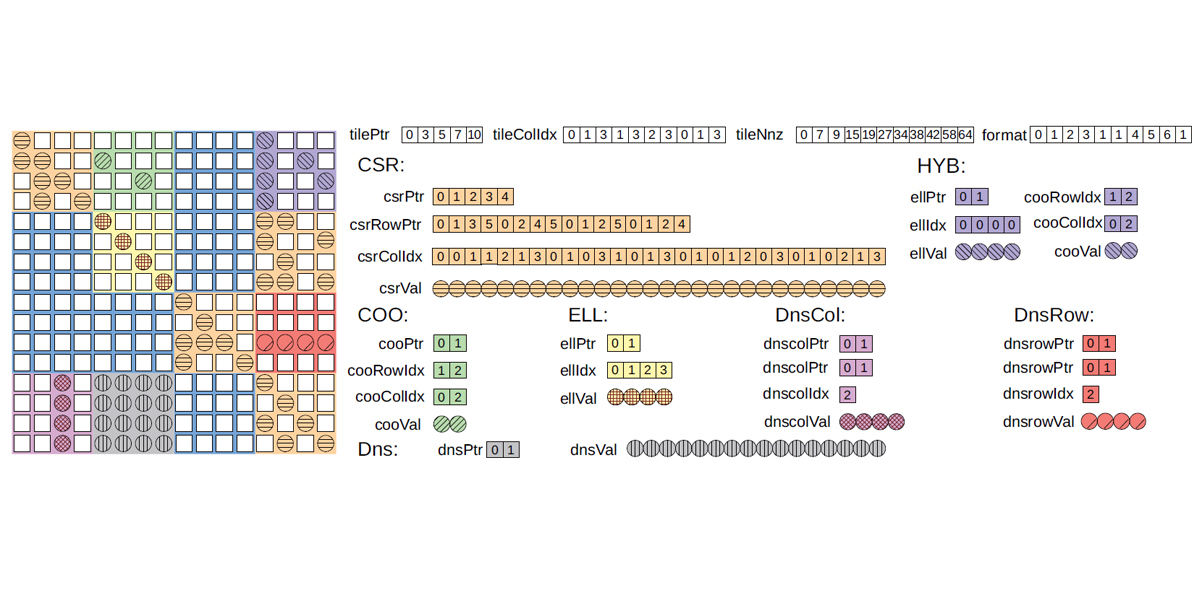
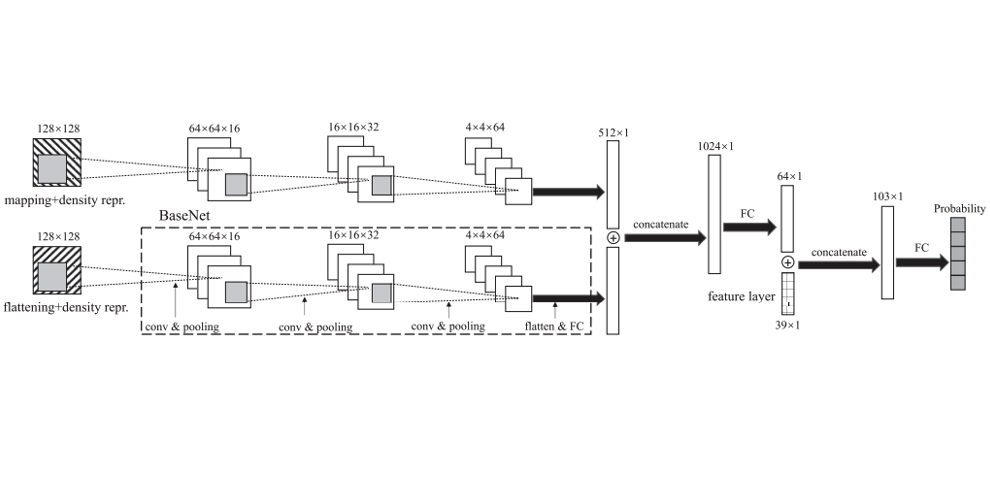
Authors: Yuyao Niu, Zhengyang Lu, Meichen Dong, Zhou Jin, Weifeng Liu, Guangming Tan
Title: TileSpMV: A Tiled Algorithm for Sparse Matrix-Vector Multiplication on GPUs
Venue: 35th IEEE International Parallel and Distributed Processing Symposium (IPDPS '21)
Year: 2021
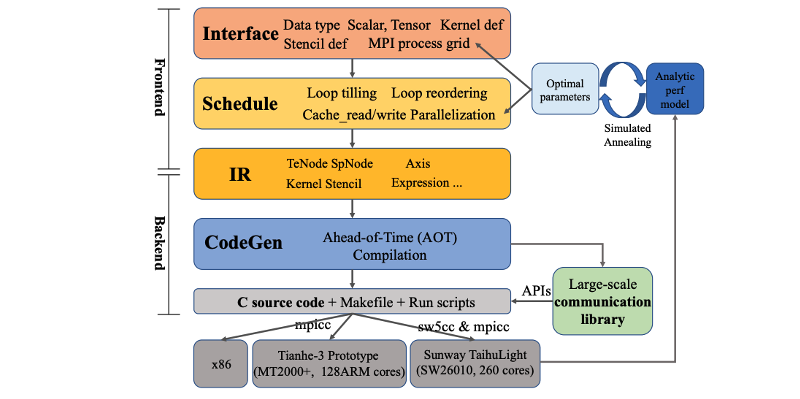
Authors: Mingzhen Li, Yi Liu, Hailong Yang, Yongmin Hu, Qingxiao Sun, Bangduo Chen, Xin You, Xiaoyan Liu, Zhongzhi Luan, Depei Qian
Title: Automatic Code Generation and Optimization of Large-scale Stencil Computation on Many-core Processors
Venue: 50th International Conference on Parallel Processing (ICPP '21)
Year: 2021
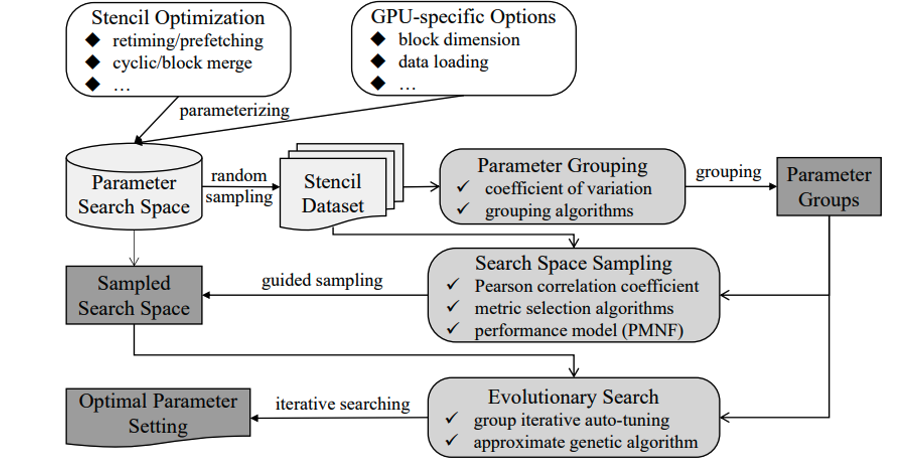
Authors: Qingxiao Sun, Yi Liu, Hailong Yang, Zhonghui Jiang, Xiaoyan Liu, Ming Dun, Zhongzhi Luan, Depei Qian
Title: csTuner: Scalable Auto-tuning Framework for Complex Stencil Computation on GPUs
Award: Best Paper Finalist
Venue: 23rd IEEE International Conference on Cluster Computing (CLUSTER '21)
Year: 2021
2020
Authors: Qingxiao Sun, Yi Liu, Ming Dun, Hailong Yang, Zhongzhi Luan, Lin Gan, Guangwen Yang, Depei Qian
Title: SpTFS: Sparse Tensor Format Selection for MTTKRP via Deep Learning
Venue: 33th International Conference for High Performance Computing, Networking, Storage, and Analysis (SC '20)
Year: 2020
Authors: Jiya Su, Feng Zhang, Weifeng Liu, Bingsheng He, Ruofan Wu, Xiaoyong Du, Rujia Wang
Title: CapelliniSpTRSV: A Thread-Level Synchronization-Free Sparse Triangular Solve on GPUs
Venue: 49th International Conference on Parallel Processing (ICPP '20)
Year: 2020
Authors: Xiaosong Yu, Huihui Ma, Zhengyu Qu, Jianbin Fang, Weifeng Liu
Title: NUMA-Aware Optimization of Sparse Matrix-Vector Multiplication on ARMv8-based Many-Core Architectures
Venue: 17th IFIP International Conference on Network and Parallel Computing (NPC '20)
Year: 2020
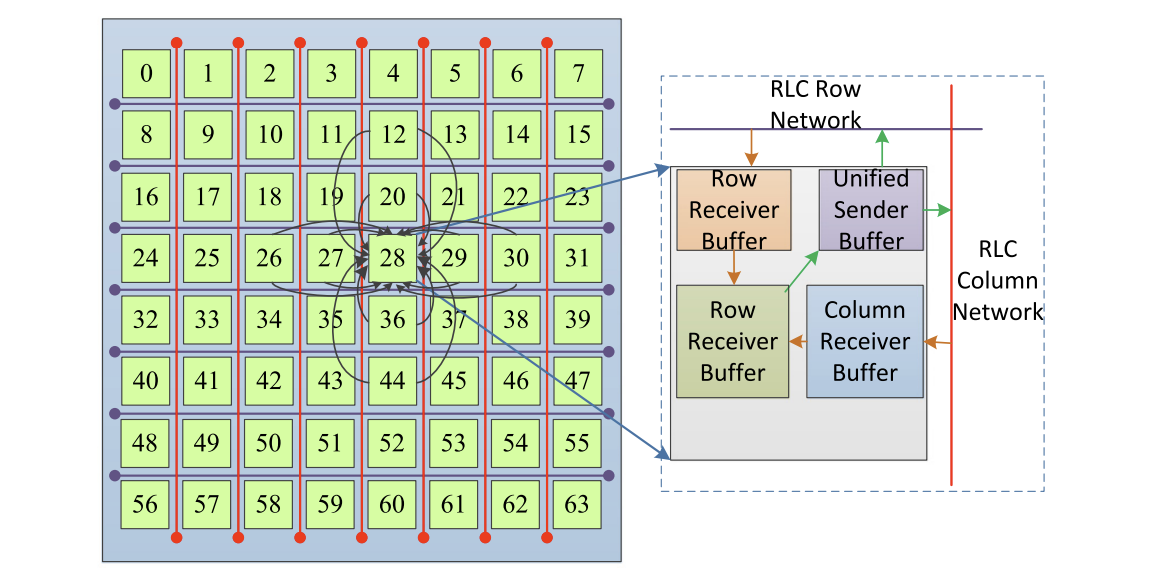
2019
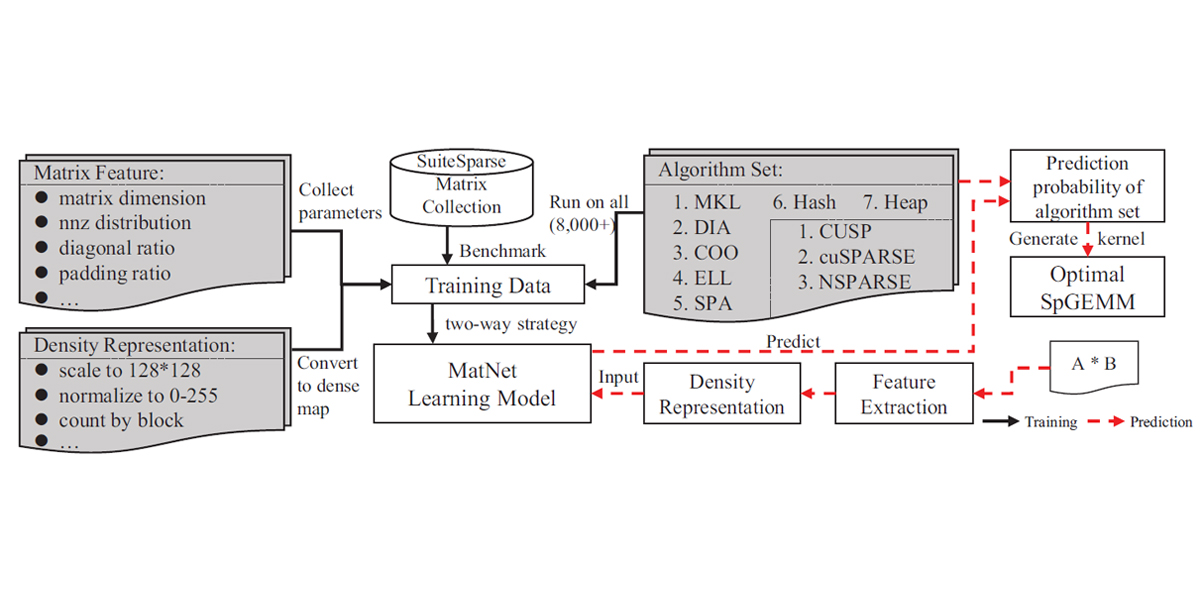
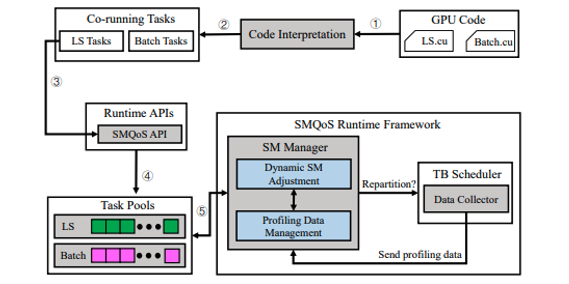
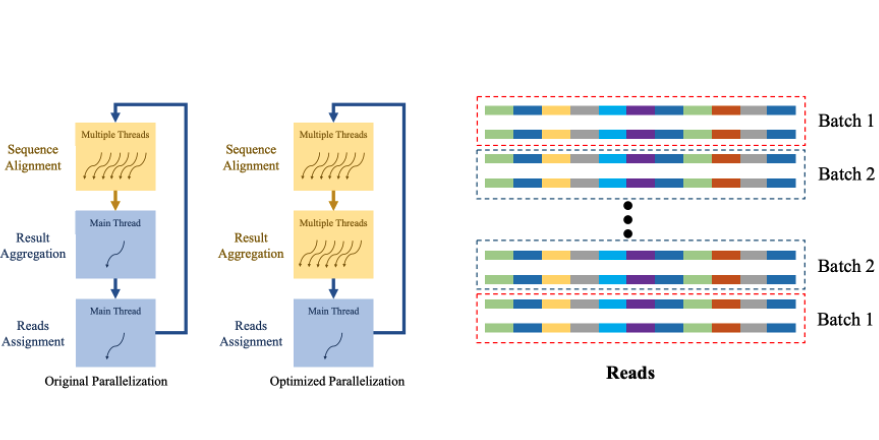
Authors: Ming Dun, Yunchun Li, Xin You, Qingxiao Sun, Zerong Luan, Hailong Yang
Title: Accelerating De Novo Assembler WTDBG2 on Commodity Servers
Venue: 19th IEEE International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP '19)
Year: 2019
2018
Authors: Xinliang Wang, Weifeng Liu, Wei Xue, Li Wu
Title: swSpTRSV: A Fast Sparse Triangular Solve with Sparse Level Tile Layout on Sunway Architectures
Venue: 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP '18)
Year: 2018
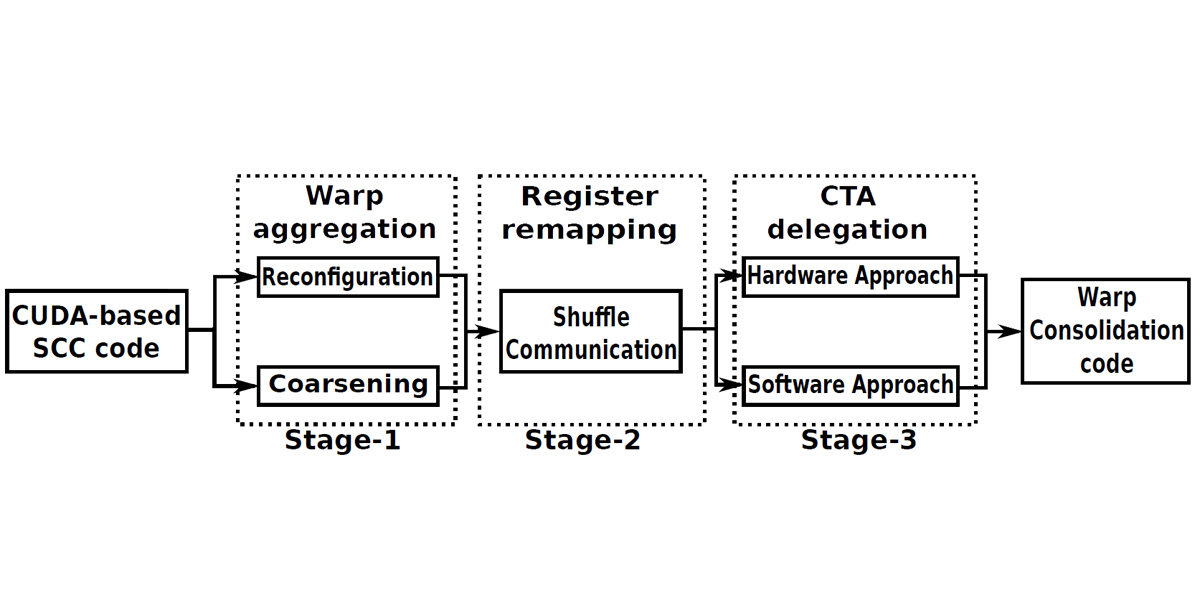
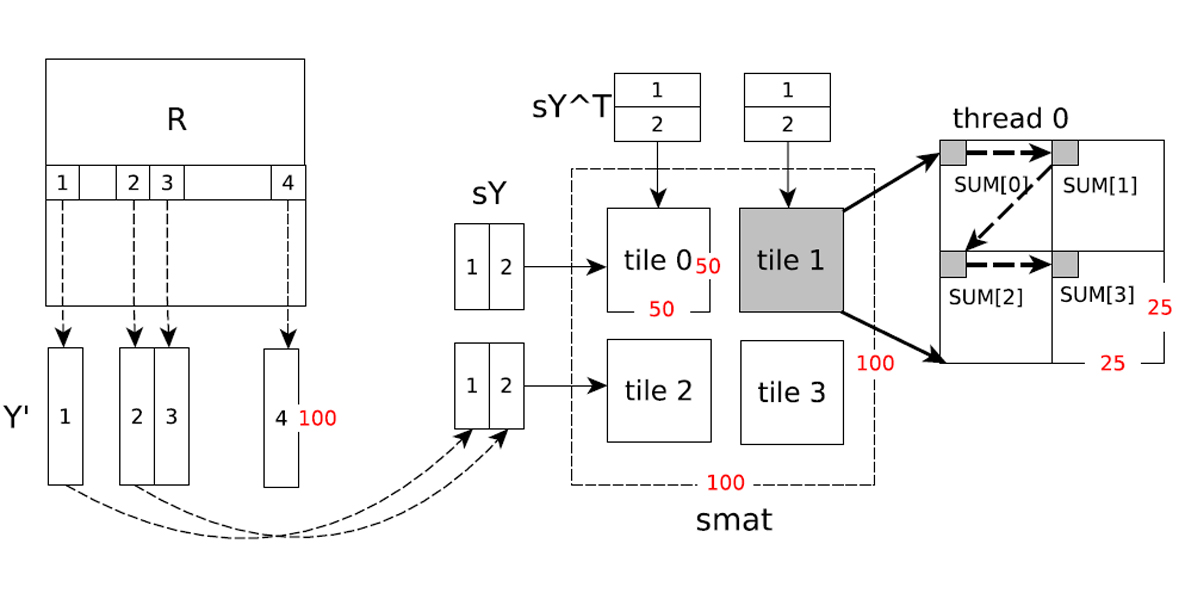
Authors: Jing Chen, Jianbin Fang, Weifeng Liu, Tao Tang, Canqun Yang
Title: clMF: A Fine-Grained and Portable Alternating Least Squares Algorithm for Parallel Matrix Factorization
Venue: Future Generation Computer Systems (FGCS)
Year: 2018
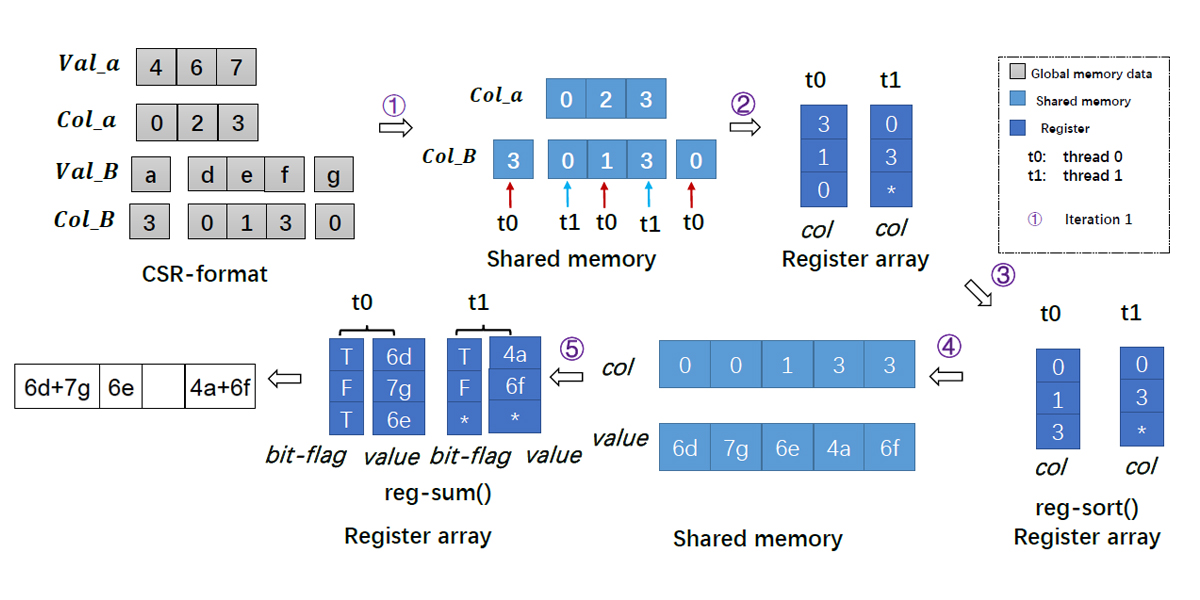
2017
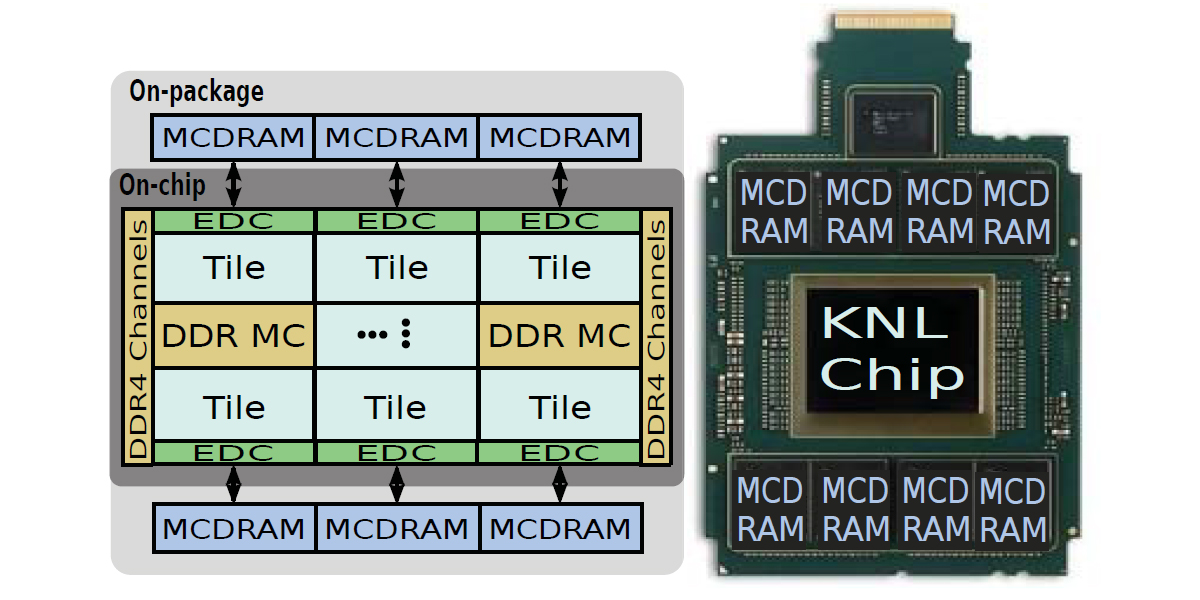
Authors: Ang Li, Weifeng Liu, Mads R. B. Kristensen, Brian Vinter, Hao Wang, Kaixi Hou, Andres Marquez, Shuaiwen Leon Song
Title: Exploring and Analyzing the Real Impact of Modern On-Package Memory on HPC Scientific Kernels
Award: Best Paper Finalist
Venue: 30th International Conference for High Performance Computing, Networking, Storage, and Analysis (SC '17)
Year: 2017
[PDF] [Slides] [DOI] [Bibtex] [Code]
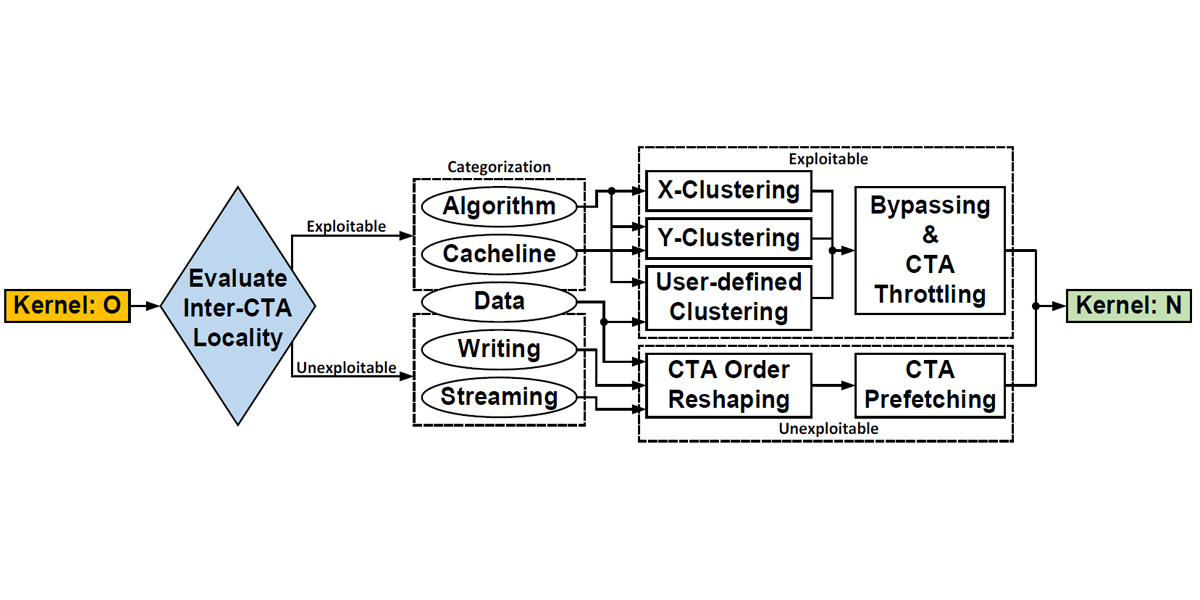
Authors: Ang Li, Shuaiwen Leon Song, Weifeng Liu, Xu Liu, Akash Kumar, Henk Corporaal
Title: Locality-Aware CTA Clustering for Modern GPUs
Award: HiPEAC Paper Award
Venue: 22nd ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '17)
Year: 2017
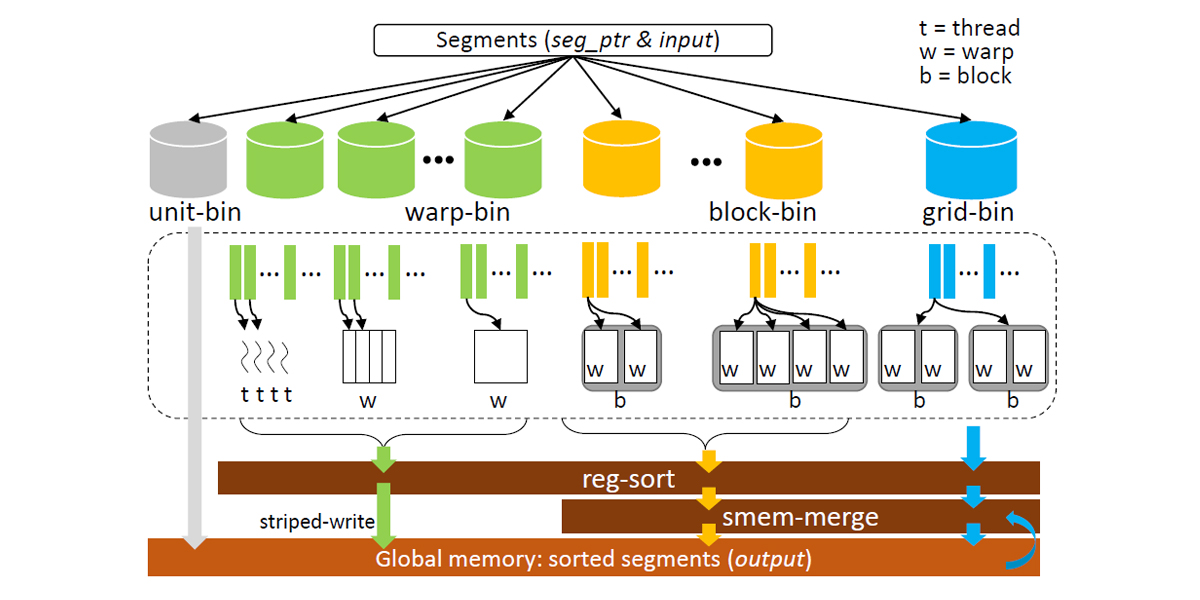
Authors: Kaixi Hou, Weifeng Liu, Hao Wang, Wu-chun Feng
Title: Fast Segmented Sort on GPUs
Venue: 31st ACM International Conference on Supercomputing (ICS '17)
Year: 2017
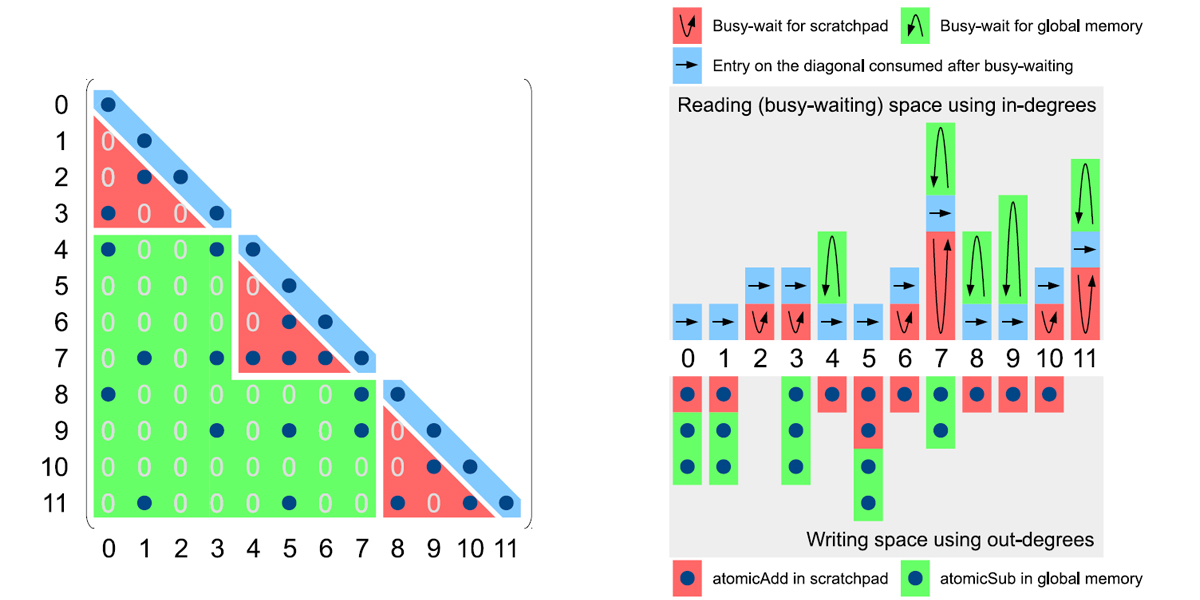
Authors: Weifeng Liu, Ang Li, Jonathan D. Hogg, Iain S. Duff, Brian Vinter
Title: Fast Synchronization-Free Algorithms for Parallel Sparse Triangular Solves with Multiple Right-Hand Sides
Venue: Concurrency and Computation: Practice and Experience (CCPE)
Year: 2017
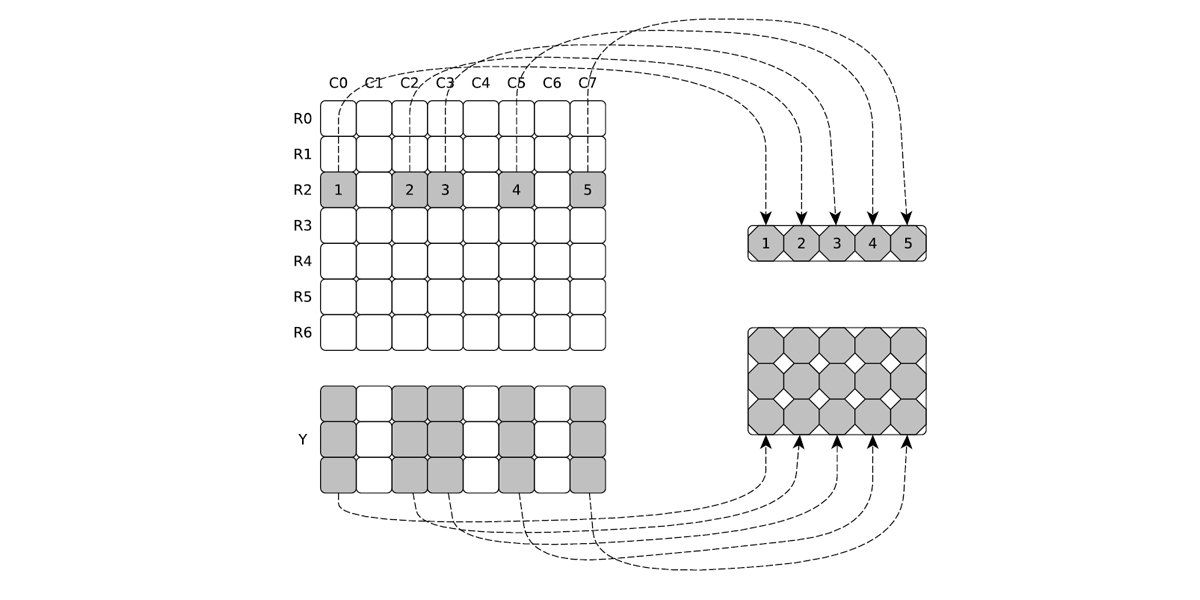
Authors: Jing Chen, Jianbin Fang, Weifeng Liu, Tao Tang, Xuhao Chen, Canqun Yang
Title: Efficient and Portable ALS Matrix Factorization for Recommender Systems
Venue: 6th International Workshop on Parallel and Distributed Computing for Large Scale Machine Learning and Big Data Analytics (Parlearning '17, held with IPDPS '17)
Year: 2017
2016
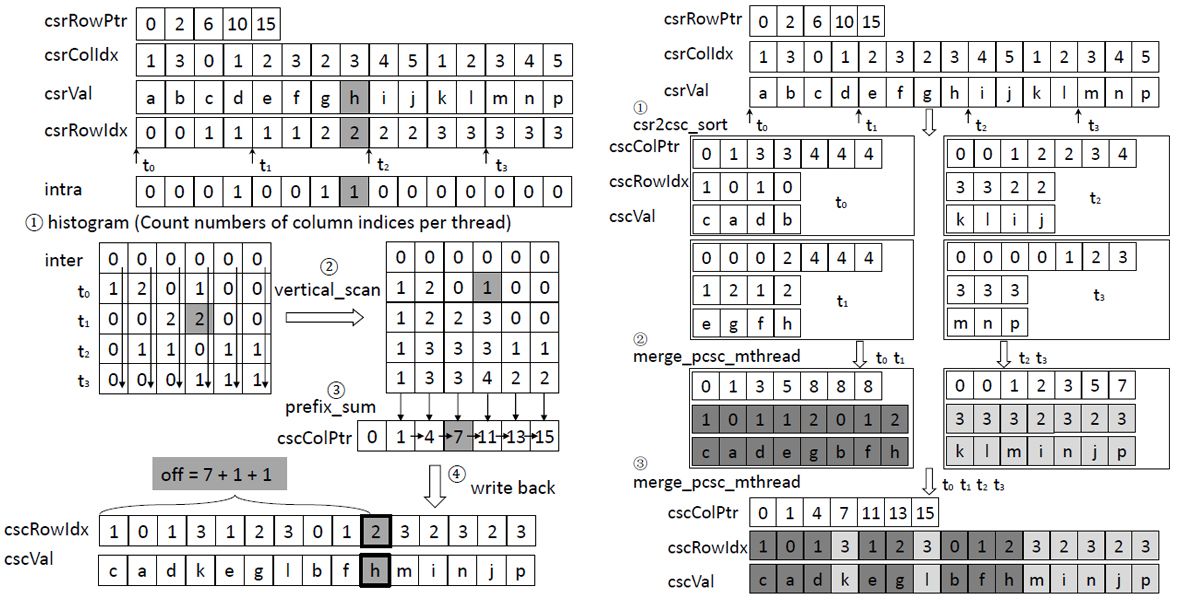
Authors: Hao Wang, Weifeng Liu, Kaixi Hou, Wu-chun Feng
Title: Parallel Transposition of Sparse Data Structures
Venue: 30th ACM International Conference on Supercomputing (ICS '16)
Year: 2016
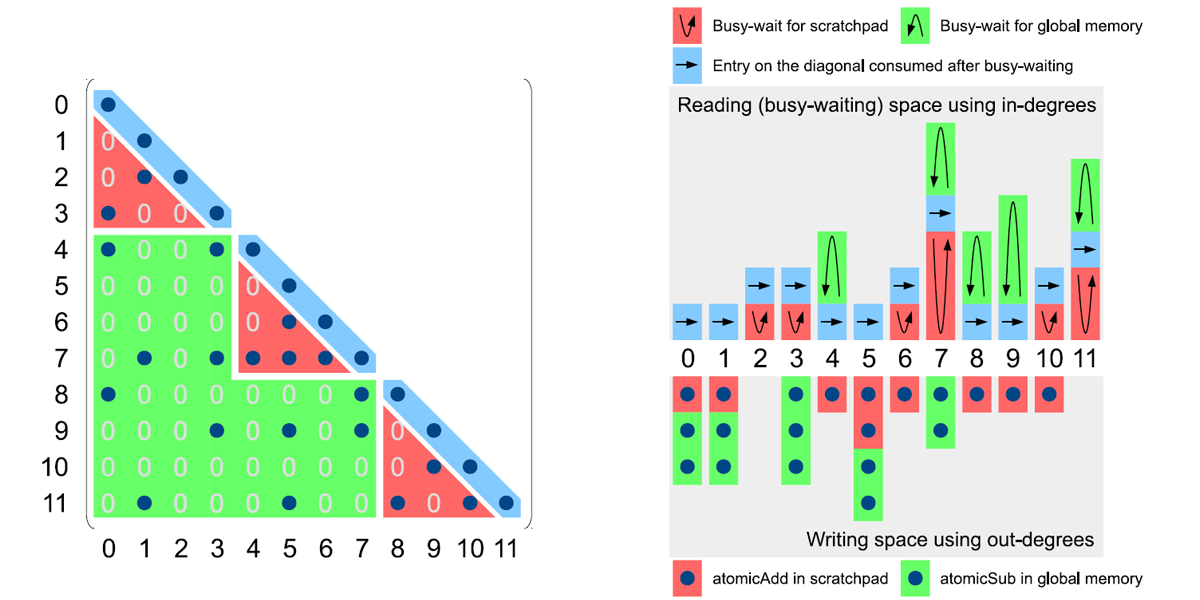
Authors: Weifeng Liu, Ang Li, Jonathan D. Hogg, Iain S. Duff, Brian Vinter
Title: A Synchronization-Free Algorithm for Parallel Sparse Triangular Solves
Venue: 22nd International European Conference on Parallel and Distributed Computing (Euro-Par '16)
Year: 2016
2015
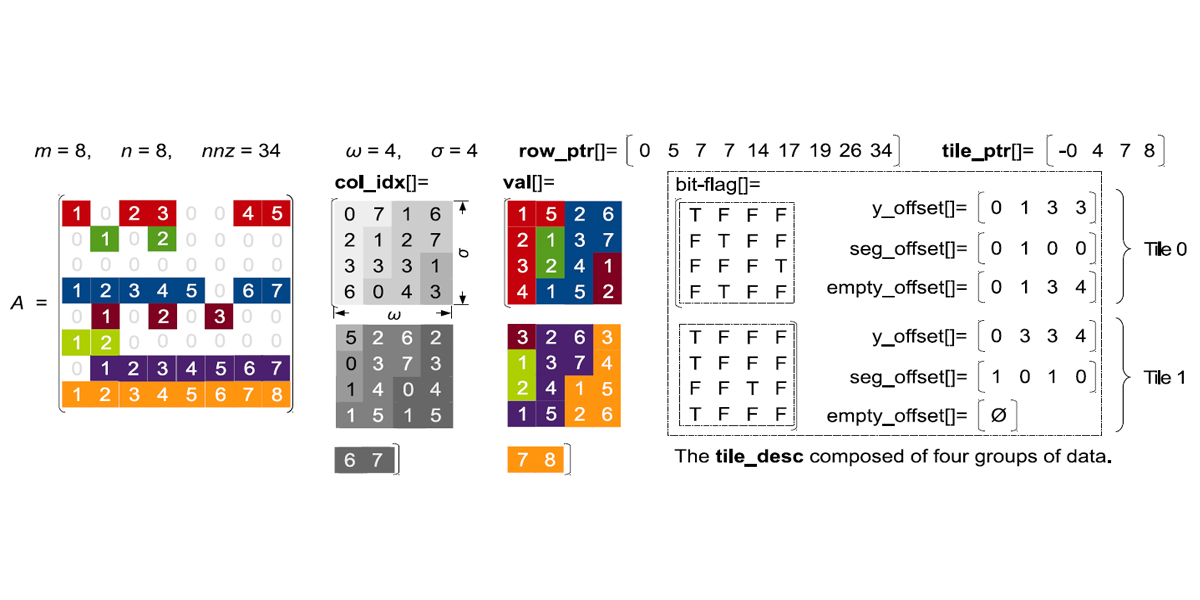
Authors: Weifeng Liu, Brian Vinter
Title: CSR5: An Efficient Storage Format for Cross-Platform Sparse Matrix-Vector Multiplication
Venue: 29th ACM International Conference on Supercomputing (ICS '15)
Year: 2015
[PDF] [Slides] [DOI] [Bibtex] [Source code (avx2, avx512, knc, cuda, opencl-amd, opencl-nvidia)]
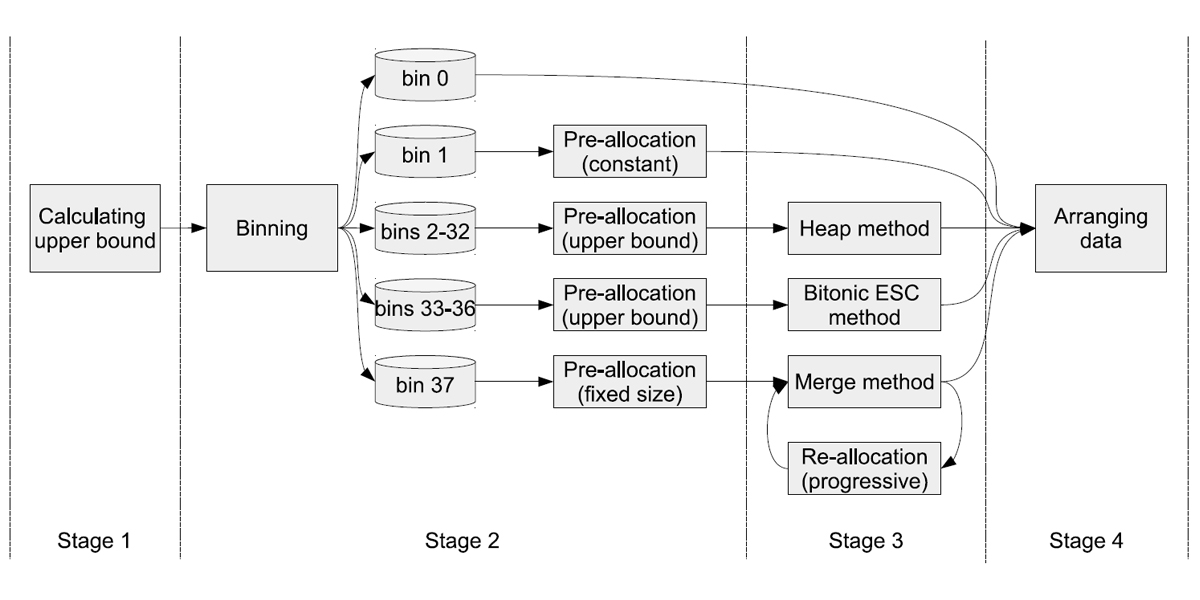
Authors: Weifeng Liu, Brian Vinter
Title: A Framework for General Sparse Matrix-Matrix Multiplication on GPUs and Heterogeneous Processors
Venue: Journal of Parallel and Distributed Computing (JPDC)
Year: 2015
Authors: Weifeng Liu, Brian Vinter
Title: Speculative Segmented Sum for Sparse Matrix-Vector Multiplication on Heterogeneous Processors
Venue: Parallel Computing (PARCO)
Year: 2015
2014
Authors: Weifeng Liu, Brian Vinter
Title: An Efficient GPU General Sparse Matrix-Matrix Multiplication for Irregular Data
Venue: 28th IEEE International Parallel & Distributed Processing Symposium (IPDPS '14)
Year: 2014